没想到继续更文已经是一个月半以后了。立个小小的 flag,到年底把 Go 基础与浅层的内核过一遍。保持两天一更的节奏。还是继续接着上期说的内存管理。了解了内存管理抽象的基础概念之后,来看一下一些具体的实现。
虚拟内存的分布
首先来看一下虚拟内存是如何布局的,这部分其实算是操作系统的内容。在《The Linux Programming Interface》这本书中提到了一张图,描述了 32 位操作系统大致的虚拟地址空间的分布是怎样的:
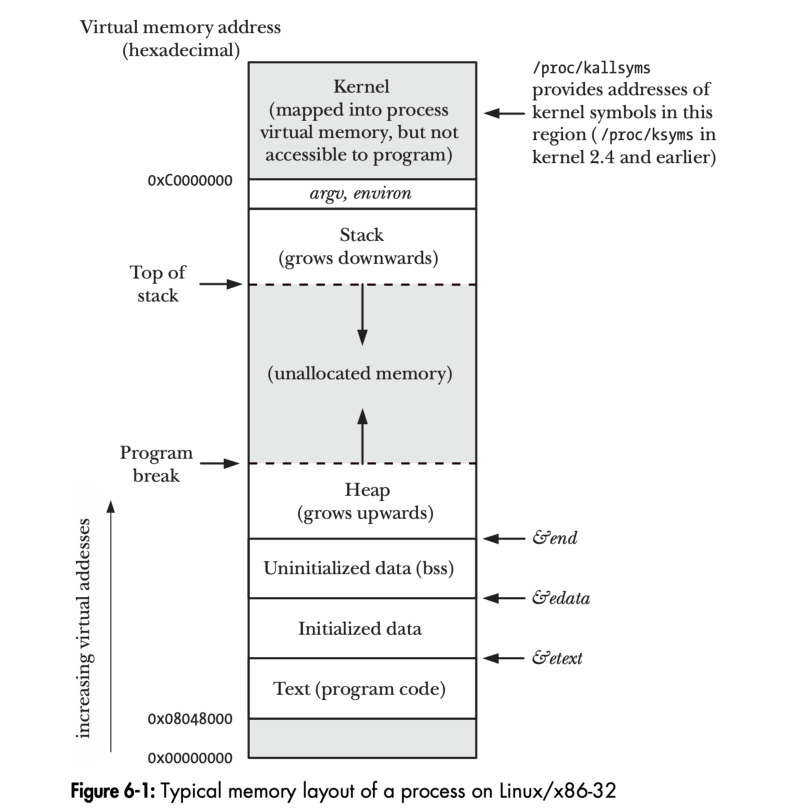
因为是 32 位操作系统,所以总的地址空间是 4 GB。可以看到上方是高地址,下方是低地址,所以可以看到以下几个特征:
- 栈 Stack 是从高地址向低地址增长的。
- 堆 Heap 是从低地址向高地址增长的。
- 调整堆顶一般来说是调整的 Program break。
然后再来看看我们常用的 64 位系统中进程虚拟内存的分布是怎样的,摘自网络:
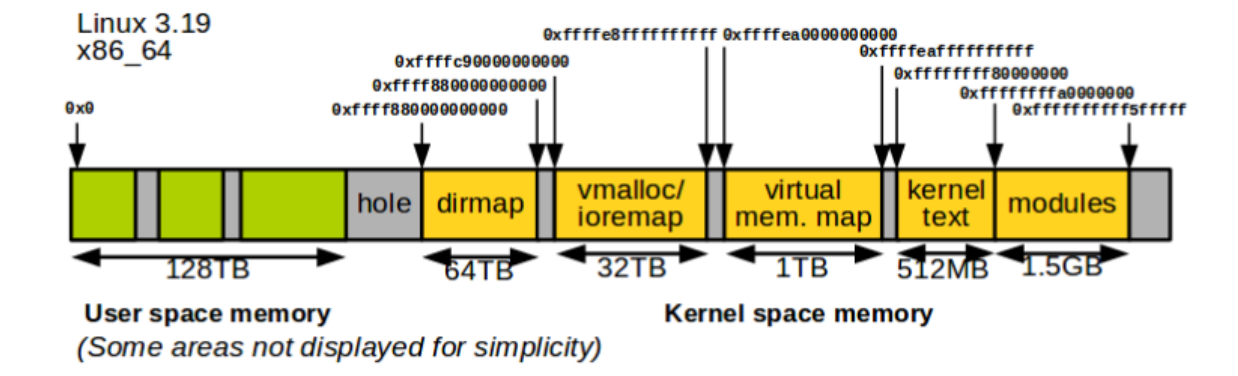
这张图可能不是很准确,感兴趣可以去官方文档,描述更加详细:https://www.kernel.org/doc/html/latest/x86/x86_64/mm.html 。
可以看到 64 位操作系统可使用的虚拟内存空间是增加的,并且基本上都是以 TB 为单位。但通过对比功能可以发现,其实 64 位内存的整体布局和 32 位的内存布局大差不差。
前面说到的都是单线程的情况,而在 Go 中我们会经常用到多线程,那么多线程的情况下,进程虚拟内存又是怎么分布的呢?一图就懂:
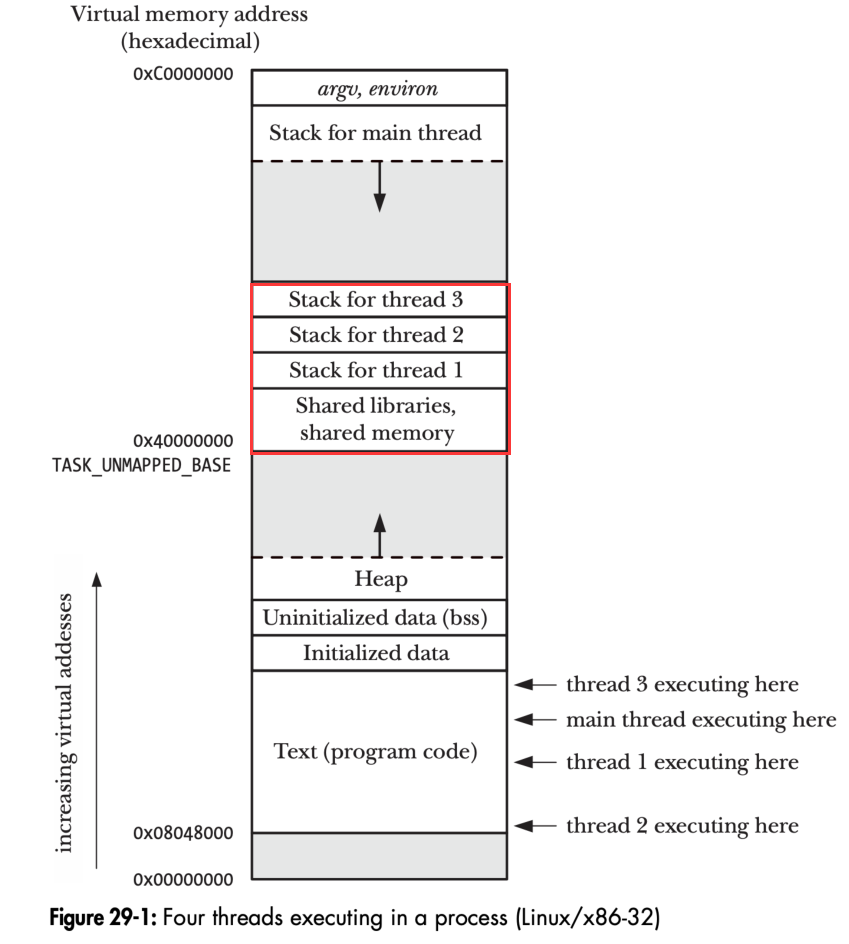
相比单进程,可以看到栈的变化最大。主线程的栈还是从上往下增长,但是其他的线程会分布在中间,并且中间会穿插动态链接库 Shared libraries、共享内存 shared memory。
而堆空间没有什么变化,但也意味着它对其他线程来说都是公用的。所以线程要访问堆上的东西都一般是需要加锁的。
OK,了解了虚拟内存地址分布情况,那么是谁来对内存进行分配呢?没错,有请下一位主角登场。
内存分配器
内存分配器 Allocator,理论上分为两种:
- 线性分配器 Bump / Sequential Allocator
- 空闲链表分配器 Free List Allocator
线性分配器在分配内存时都是从虚拟内存中扒一点出来,下次还要分配又继续扒,继续扒 … 如果中间有内存释放掉了 free,这些线性分配器也不会对这些被释放掉的内存进行复用。而如果我们现在的需求就是要对空间进行复用的话,就需要额外的链表来维护被释放掉的块,这也叫做空闲链表分配器。
一般线性分配器由于自身的局限,应到的地方少,所以我们继续深入研究一下空闲链表分配器。我们在看一些网文或博客的时候经常会看到,实现它的算法会有很多中类型,不过大致也就以下四种:
- 每次遍历从头开始 First-Fit
- 从上次成功分配内存地址的地方开始遍历(又叫环形匹配算法) Next-Fit
- 遍历整个链表找到最合适的空间 Best-Fit
- 分级匹配算法 Segregated-Fit
前三种算法或多或少都有点问题,而第四种完全不一样了。它是指将内存块按照不同的大小分为很多级别数组,每个数组中的内存大小都是一样的。比如 [8B,8B,8B…], [16B, 16B, 16B…], …, [8K, 8K, …] 。每次要分配的时候,都去找大小最接近的块,直接塞进去。工业界大多的算法都是采用这种算法。在 Go 语言中其实也是这种算法的一个变种,GO 语言的内存分配器便是这种模式,因为可以减少分配所产生的内存碎片。
下期继续讲解常用的内存分配函数以及 Go 语言中内存如何分配。