Go 语言在内存管理中申请使用稀疏堆时,使用系统调用 mmap ,因此可以分配出不连续的地址(而不是通过系统调用 brk 来调整虚拟空间里堆的 program break 来分配连续内存地址)。在使用稀疏堆时,整体的堆内存怎样增长的呢?
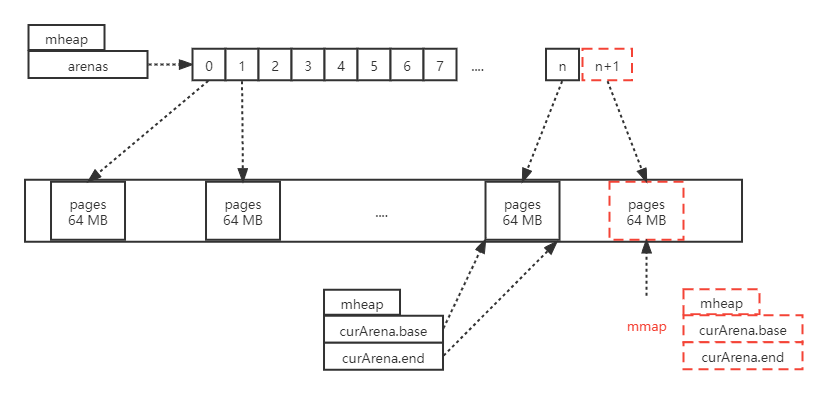
较大的内存块 arenas 其实是个大的指针数组,每个指针就是 mheap arena 结构,它会指向具体的 64 MB 的内存,在当前的 mheap 结构中还会维护最后一个起始位置和结束地址。一旦分配内存的时候真实结束地址超过了 mheap 结束地址时,说明还需要从操作系统要更多虚拟内存,这时还是执行 mmap 再分配一个 64 MB 的地址空间,并且维护好当前的数据结构,把原来的 n 变为 n+1 相当于增加了一个元素。
在 Go 语言中除了从操作系统申请内存的方式以外,在分配时还要区分内存大小,有三种分配大小分类:
- Tiny:size < 16 bytes && has no pointer(noscan)
- Small: has pointer(scan) || (size >= 16 bytes && size <= 32KB)
- Large: size > 32KB
并且,内存分配器在 Go 语言中为了做一些优化,维护了一种多级结构:
- mcache:与 P 绑定,本地内存分配操作,不需要加锁。
- mcentral:中心分配缓存,分配时需要上锁,不同 spanClass 使用不同的锁。
- mheap:全局唯一,从 OS 申请内存,并修改器内存定义结构时,需要加锁,是个全局锁
在距离应用代码最近的 P 的位置,每个 P 都绑定了 mcache 结构,这个结构会有大小相应的缓存。本地分配内存时会优先从 mcache 中找,如果找不到就要从全局的缓存中去找,如果还是没有相应的内存块可以用的话,就需要去全局唯一的 mheap 请求,从操作系统重新划分一部分内存出来。不过 mheap 还有 area 结构,如果 area 还没有用完的话还是会从 area 里面去切分,如果用完了就会去操作系统中去申请。
这个过程中只有 mcache 的分配过程是不加锁的,mcentral 中锁的力度会小一些,到全局唯一锁 mheap 的时候锁的力度就非常大了,并且如果在生产环境中如果触发频繁,那么性能很可能有问题。得益于这种多级缓存的机制,实际线上还是是难触发这种全局唯一锁的。
在分级堆上,其大小有很多 spanClass 分类:
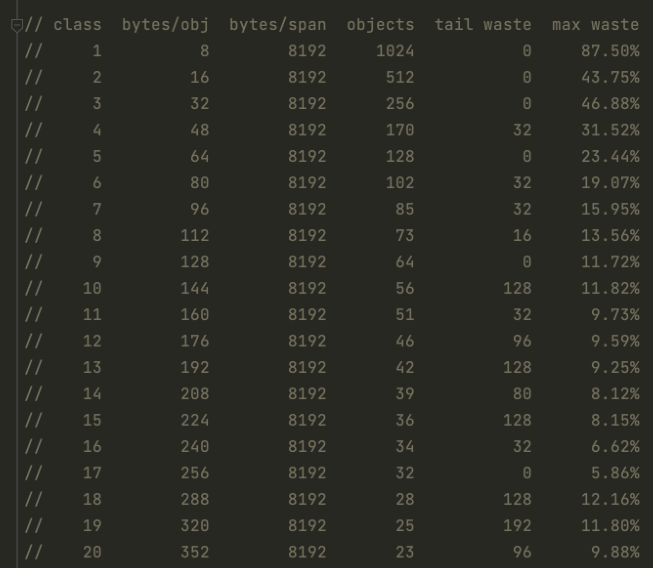
这里只是列举了一部分,其实从最左侧 class 看总共 spanClass 有 66 个种类型,从 8 bytes (第二列)到 32 KB。Class 0 的位置预留给了大对象 large 分配了。
在第一行中,每个 class 里面其实都对应了 8 字节大小的分配(第二列),span 总共有 8 kb(第三列),也就是说可以放 1024 个对象(第四列)。如果所有的对象都正好 8 字节的话,尾部也不会内存浪费(第五列)。
以上的分级算法其实是为了解决内存碎片而设计的,但我们可以看出,这种设计也没办法完全消除内存碎片(第五列)。所以在不同的大小里面还是可能会有尾部浪费的情况,相比整块浪费还是比较少的(如14行,剩余 128 相比于丢弃 8192,差不多 1% 的剩余率)。
在我们了解了三种不同类型的分配路径和整体内存结构的 67 种 class,我们看文字还是比较难懂,再来看一组图:
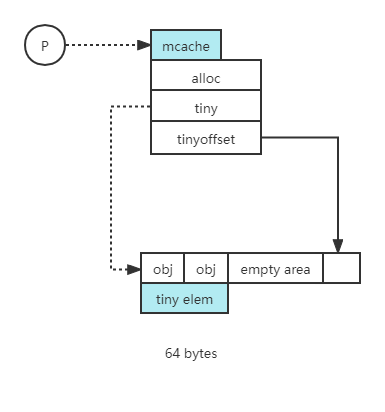
Tiny 分配稍微为复杂。可以看出 mcache 是和每个 P 绑定的,如果当前 app 想申请内存分配一个小对象,应用要分配内存还得是从 mcache 中去找。而 mcache 为了做优化还有个 tiny 的指针,会指向 tiny 的 tiny elem 对象,这些对象是可以再存放多个这种微对象的。比如第一个对象是 0 到 8 字节,第二个对象是 8 到 16 个字节,只要 tiny elem 有足够的空间就能够一直往里面存放,直到满为止。
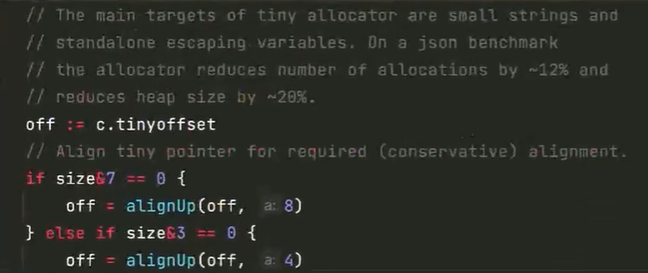
从 GC 源代码 malloc.go 中可以看到官方对于这些微对象处理的好处:官方专门设计了这么复杂的 tiny allocator,对于非常小的 string 对象和一些单独逃逸的变量是有好处的。在 json marshal 情况下会把整体的内存分配减少 12 %,并且整个堆的大小能够减少 20%。
以上都是说 tiny elem 能够存放下对象,而如果满了、存放不下了怎么办呢?就需要去从 mcache 的 alloc 结构中去找。这个 alloc 结构其实就是前面 67 种结构类型大小的乘以 2,总共有 134 个数组。并且它会按照对象中是否有指针去做区分的,所以需要原来大小的两倍。比如当前对象分配在堆上,并且它内部还有指针,那么就会是一个 scan 类型的对象,如果不包含指针就是 noscan 类型对象。
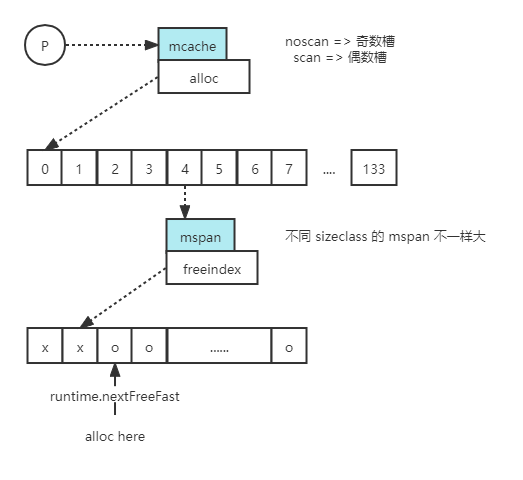
一般而言,noscan 对象分配在奇数槽位,scan 对象分配在偶数槽位。这里很重要的是:tiny 对象本地缓存用完之后都是从第五个槽位开始找的。通常是申请的 64 字节的空间大小,就相当于从 mspan 中去划分一个对象出来,即一个 tiny elem。
还有一种情况是 mcache 的 alloc 这个大数组也满了,就需要从全局去找,用到 mheap 里的 central 的缓存,去调用 runtime 中的 mcache.refill 方法。
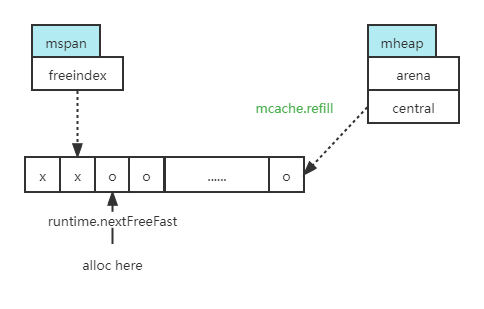
mcache.refill 会从 central 缓存中去拿一个空的 mspan 出来、填好。这里也需要注意,从全局拿出来的槽不一定全是空的,可能有些位被分配了,但只要有空的位置就可以被利用起来、做一些内存分配的工作。
OK,做个小结。一开始我们是从 tiny 和 tinyoffset 中找空间,如果找不到就会去 alloc 这个列表中去找;如果本地列表也找不到就会全局中去找,全局找不到的时候就会触发一些内存分配操作,这个内存分配的操作也是一级一级往后传递的。其实很多系统的流程也是这么设计的,比如互联网的多级缓存。
以上的图标注说当前的流程不仅是 tiny alloc 在各种情况下内存分配的流程,其实也是 small Allocator 的流程,这就不详细展开。Small alloc 相比 tiny alloc 除了没有 tiny 和 tinoffset 其余流程完全一致。
而 Large alloc 对象和前面两个对象就不一样了。这个大对象分配会直接越过 mcache、mcentral,直接从 mheap 进行相应数量的 page 分配。目前, pageAlloc 结构已经经过了多个版本的变化,从:freelist → treap → radix tree(go1.14.x 以后),查找时间复杂度越来越低,结构越来越复杂。
这里再回顾一下 Refill 流程:
- 本地 mcache 没有触发时 (mcache.refill)
- 从 mcentral 里的 non-empty 链表中找可以用的 mspan(mcentral.cacheSpan)
- 没找到,会尝试做些清理工作 sweep mcentral 的 empty, insert sweeped → non-empty(mcentral.cacheSpan)
- 没找到,会去增长 mcentral,尝试从 arena 获取内存(mcentral.grow)
- arena 如果还是没有就会向操作系统申请(mheap.alloc)
最终还是会将申请到的 mspan 放在 mcache 中。
最后将整个堆内存管理的数据结构大地图放出来:
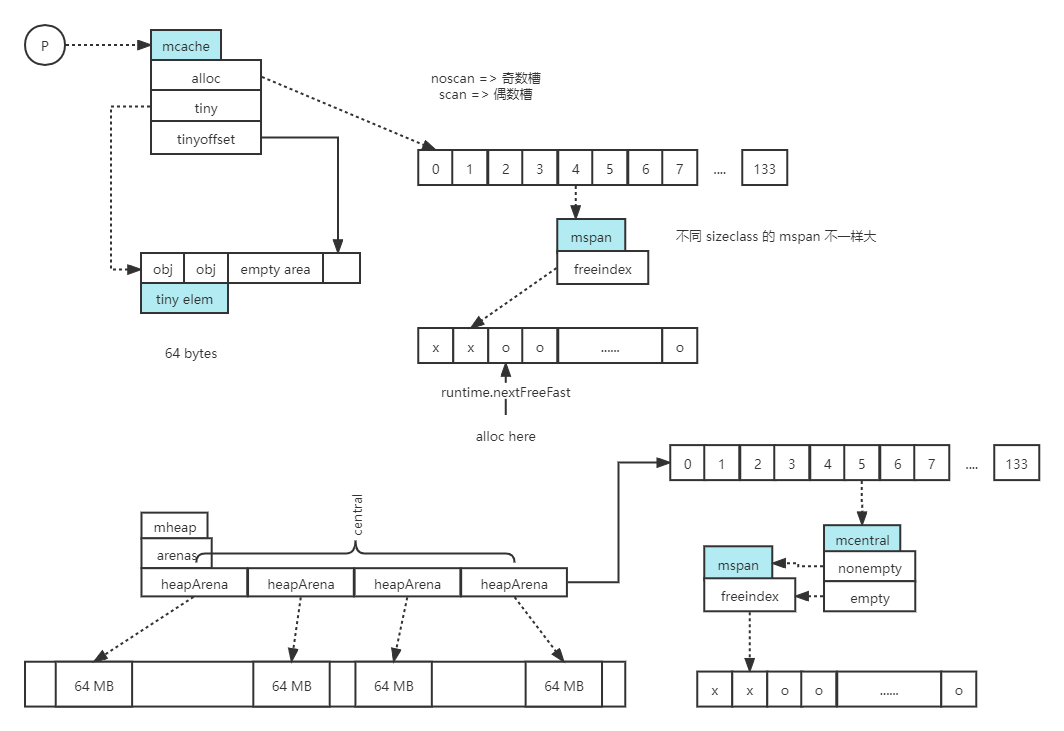
初学内存管理还是有些困难,总共以上六个环节,一点点慢慢就搞懂了。需要注意的是 Go 向操作系统申请内存一般都是 64 MB 为单位。
最后最后,补充一点,一个 mspan 中会有多个 elem,所以每个 elem 会对应分配位和标记位。以下为 mspan 的放大图
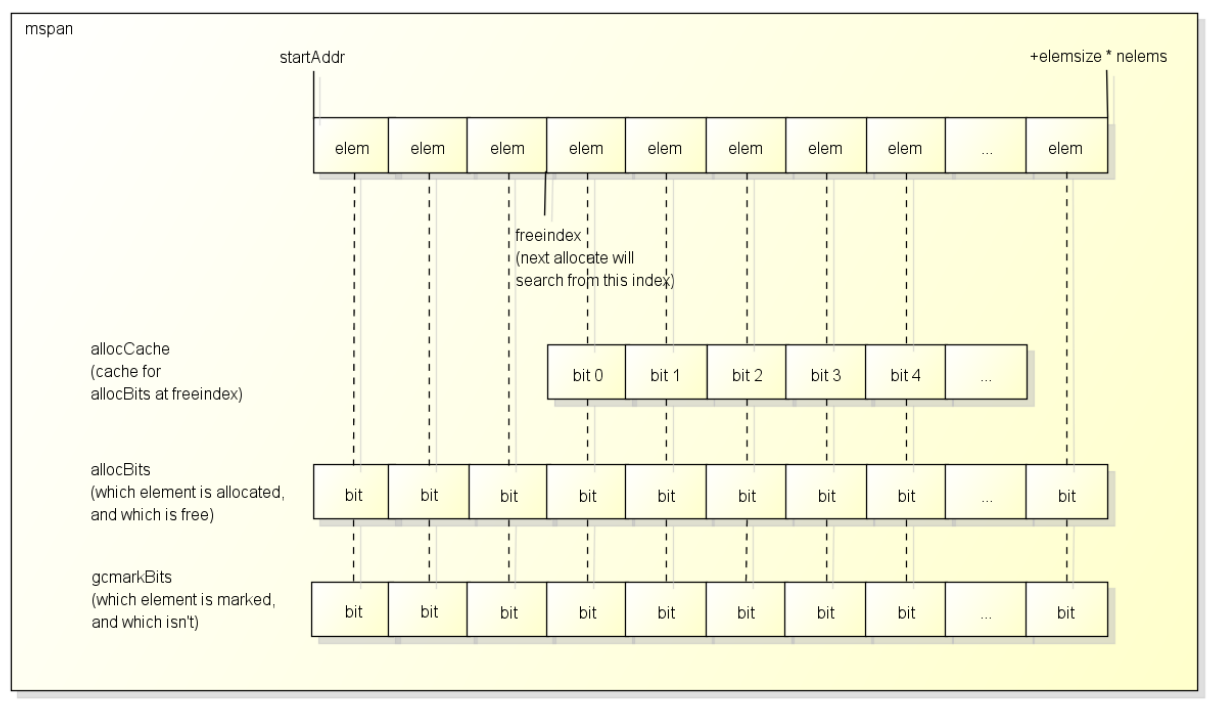
分配位是指 allocBits 的结构(一堆 bit 位)。标记位一般是指 bitmap,用来标记哪些被使用过,如 gcmarkBits 是在 gc 做标记用的。
总结,堆内存分配的整个步骤其实就是图 7 整个数据结构的六个步骤。如果要真正了解这些的运作逻辑,把六个步骤都理解清楚就 OK 了,关键的函数也在以上都标明了。