Go 语言的垃圾回收机制采用的是标记清扫。这种方法的特点在于:标记清扫完成之后,有些内存没办法被使用的,所以标记清扫很大的问题就是有很多内存碎片。我们在使用标记清扫算法的时候,需要内存分配算法能够一定程度上应对这种碎片问题,之前分析过分级分配的分配器可以在一定程度上应对这个问题。这也是为什么 Go 语言可以使用标记清扫算法,因为它使用了 tcmalloc,在一定程度上能够缓解碎片问题(但也没有解决)。
老版本 Go 语言中,标记清扫大致是以下流程:

- 最开始 Off 阶段,应用程序正常执行,可能没有调用 gc。
- 当垃圾收集开始处于 Stack scan 阶段,会做一些栈扫描,从栈和全局变量中收集到一些基本的根指针,也就是整个对象图的根,在开始收集时需要去开启 write barrier。黄色的矩形标记的是要把 write barrier enable 这种全局变量改成 True,之后所有的指针变量都需要经过这种特殊的逻辑。
- 在堆对象收集完成之后就开启了标记流程 Mark,其实就是个基础的广度优先算法,也可以当作多叉树来理解也是可以的。
- 标记结束阶段 Mark termination,因为 write barrier 存在缺陷,所以在标记完成之后还需要对有全局或者已经变更的栈做一次扫描,把已修改的指针重新进行 GC 标记,防止在 GC 阶段发生对象的漏标或者错标情况。
- 所有对象标记完成之后进入 Sweep 阶段,做一些清扫工作,这段流程之后垃圾就被回收掉了。被垃圾占用过的空间就可以被重新拿来分配。如果不需要那么多内存,那就会把分配器还给操作系统。
- 完成整个清扫、回收过程之后,把 GC 设置为 Off,也就重新回到应用程序执行阶段。
Go 语言在 1.8 版本以后,通过混合 write barrier 消除了第二个 stw 中的 stack re-scan,也就是说 stw 时间大大减少了。stw 位于图中红白的矩形块阶段,是指这段时间内只有垃圾回收在执行,应用程序是被阻塞住的,两个红色阶段都是被阻塞住的。早期版本的 stw 的时间是比较长的,因为它会扫描所有全局或者变动的栈,这里就非常耗时了。
新版本的垃圾回收流程和原来有些区别:
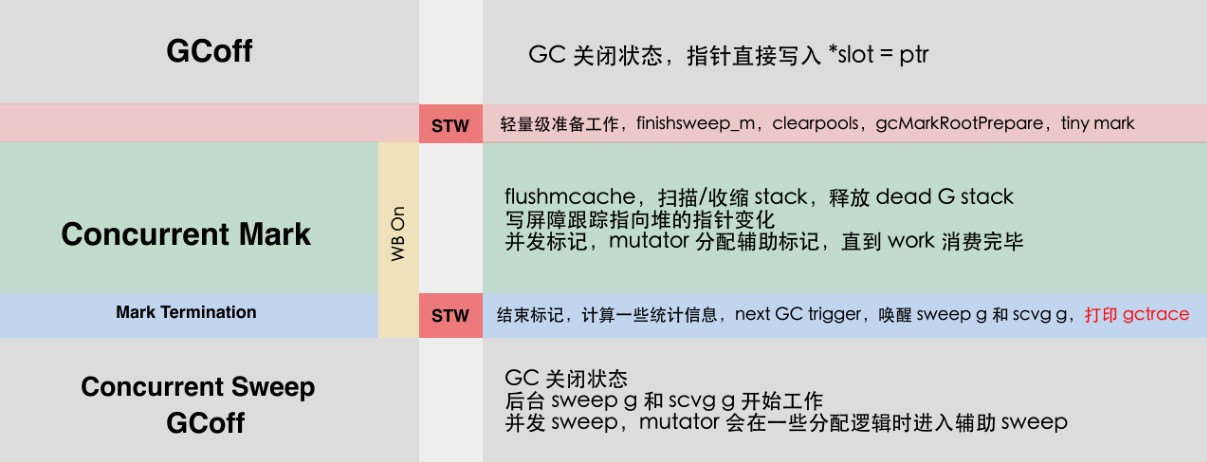
Go 官方做了些优化,第二个 stw 过程中不用去做全栈扫描,因此时间大大缩短了。整体流程也发现了非常大的变化。如果去看了 Go 语言源码,可以发现每两三个版本垃圾回收模块的逻辑变化挺大,很多内部的实现都变了,有时候两个版本之间可能只有主函数或关键流程差不多。因此我们也可以得出结论:Go 语言垃圾回收的模块是变化非常频繁的,如果不是工作需要或兴趣趋势,简单了解流程就行了。
在 Go 语言中,垃圾回收也会有个入口,位于 runtime 的 gcStart 函数,它会在三种情况下被触发。
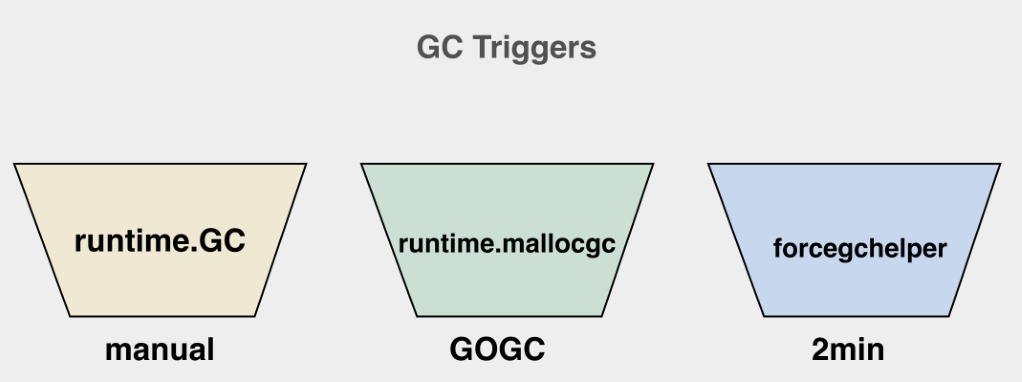
情况一:我们可以在程序中手动去调用 runtime.GC 这个函数。这个函数一般用处不大,大多是在测 GC 相关的 Bug 的时候需要去主动调用,或者主动触发用于写测试。
情况二:在做内存分配的时候,内存分配的速度超过了垃圾回收速度,会导致内存一直增长下去,最终 抛出 OOM 内存溢出异常。所以在 Go 语言中分配内存的时候,不仅会触发 GC,也会做一些协助 GC 的工作。
情况三:一个后台触发 GC 的 Goroutine。当我们的应用程序处于尖峰访问期间,比如在 1 分钟内,只有一秒的 QPS(每秒查询率) 在 1 万,其他时间段都是 10 QPS。它会在那一秒内分配非常非常多的对象,即便其他时间都是 10 QPS 但内存始终还是不能释放降下去。这种情况就需要我们定义一个主动并且强制进行 GC 的线程,去检查垃圾回收是否长时间没有被触发,如果没有就主动触发。比如 2 分钟内没有触发 GC,那么它就会主动去触发一次 GC。
OK,下期文章再继续分析 Go 语言中比较难以理解的 GC 标记过程。