我们之所以使用 Go 语言,其中一个很大的原因是它原生支持高并发,通过 Goroutine 和 Channel 完美实现。并且 Go 的并发是属于一种 CSP 并发编程模式的实现。如果我们想很好利用到这个特性,知其然知其所以然,是学习阶段最好的成果,在生产环境中遇到问题才能有的放矢。下面就从它的一些基础数据结构开始讲起。
并发内置数据结构
sync.Once
在 Go 语言的并发结构中,比较简单的是 sync.Once。可以在源码 sync/once.go 中看到代码并不多,但注释很多,还有部分我用省略号隐去了。
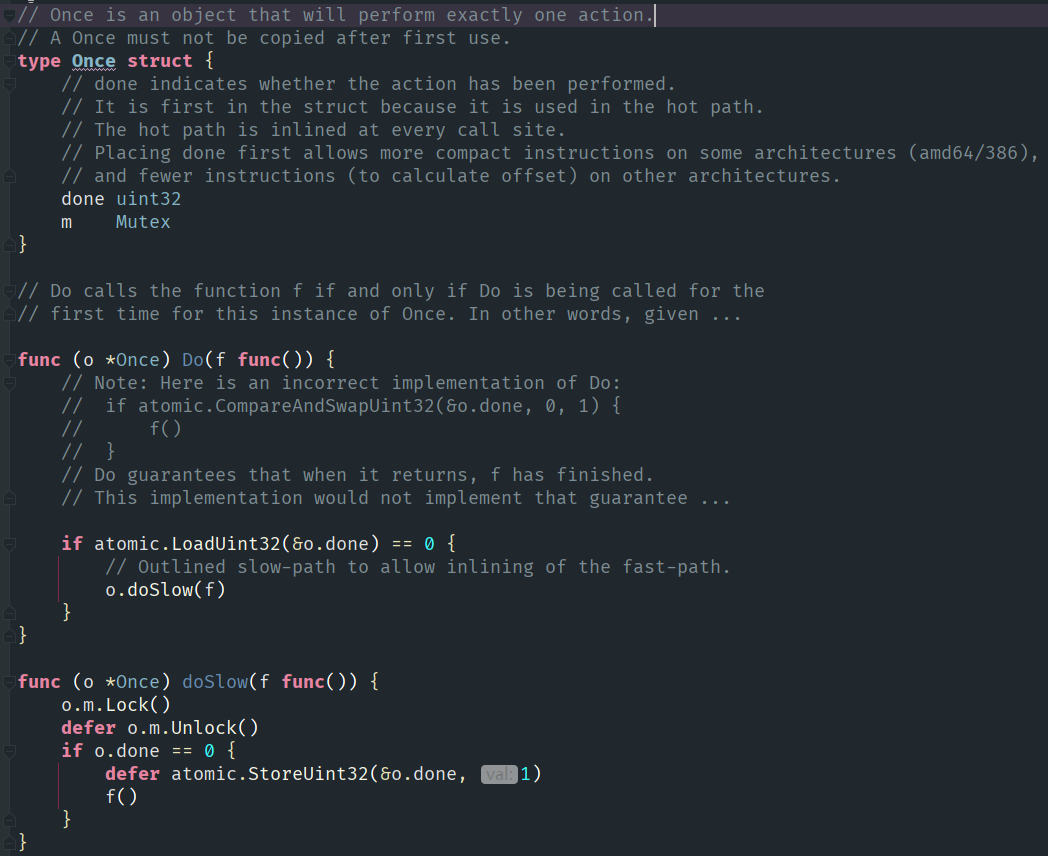
sync.Once 只有一个方法,DO。不过其中有一些要点,如果 done 被人修改了,那么就需要做一个初始化;如果是非零就可以直接返回了。也就是说 o.Do 需要保证:
- 初始化方法必须且只能被调用一次。
- Do 返回后,初始化一定已经执行完成。
以上代码虽然非常短,但我们在开发的时候还是会遇到一些问题。这时还得找官方,为什么一定要有 atomic 操作,为什么 doSlow 函数中一定要用 defer 来处理锁。官方对这些“看似”很基础的问题感到烦,于是就写了非常多的注释,让读者自己去搞懂这些问题(从图中看到)。
这里的功能对于业务层开发的 Gopher 来说比较简单:有个全局资源,只能够初始化一次,需要初始化完成之后去执行一些操作,不过初始化的入口可能会被很多地方调用到。这种情况很常见,一方面是因为我们在做网络编程的时候要处理连接,如果多次 close 连接会出现诡异的错误。所以有很多网络程序中的 Connection 对象再加个 Once 对象,来保证关闭只会执行一次。
sync.Pool
这个结构用的场合非常非常多,不过主要在两种场景使用:
- 进程中 inuse_objects 数过多,gc mark 消耗大量 CPU。这种情况多出现于当我们发现程序吞吐量很低时。
- 进程中 inuse_objects 数过多,进程 RSS 占用过高。这种情况是我们的程序可能运行在比较苛刻的环境下,比如 docker 中内存限制,只有 2GB 的内存。如果超过的话这个进程就会被 kill。
基本的使用方法是在请求生命周期开始时,调用 pool.Get 去获取缓存的 struct 或者 slice,当请求结束时,再调用 pool.Put 把之前拿出来的对象再放回去。在这种流程在开源项目 fasthttp 中有大量应用:https://github.com/valyala/fasthttp/blob/b433ecfcbda586cd6afb80f41ae45082959dfa91/server.go#L402 这个框架对我们几乎能够看到的结构都做了一次以上的复用,也就是各种花式的 sync.Pool。并且因为它在内存优化方面做得比较多,所以它的性能也要比其他几乎所有的第三方 http 库和官方的库要好一些(当然这种优化都是有代价的)。
因为 sync.Pool 的逻辑结构比较复杂,还是看图来的容易点:
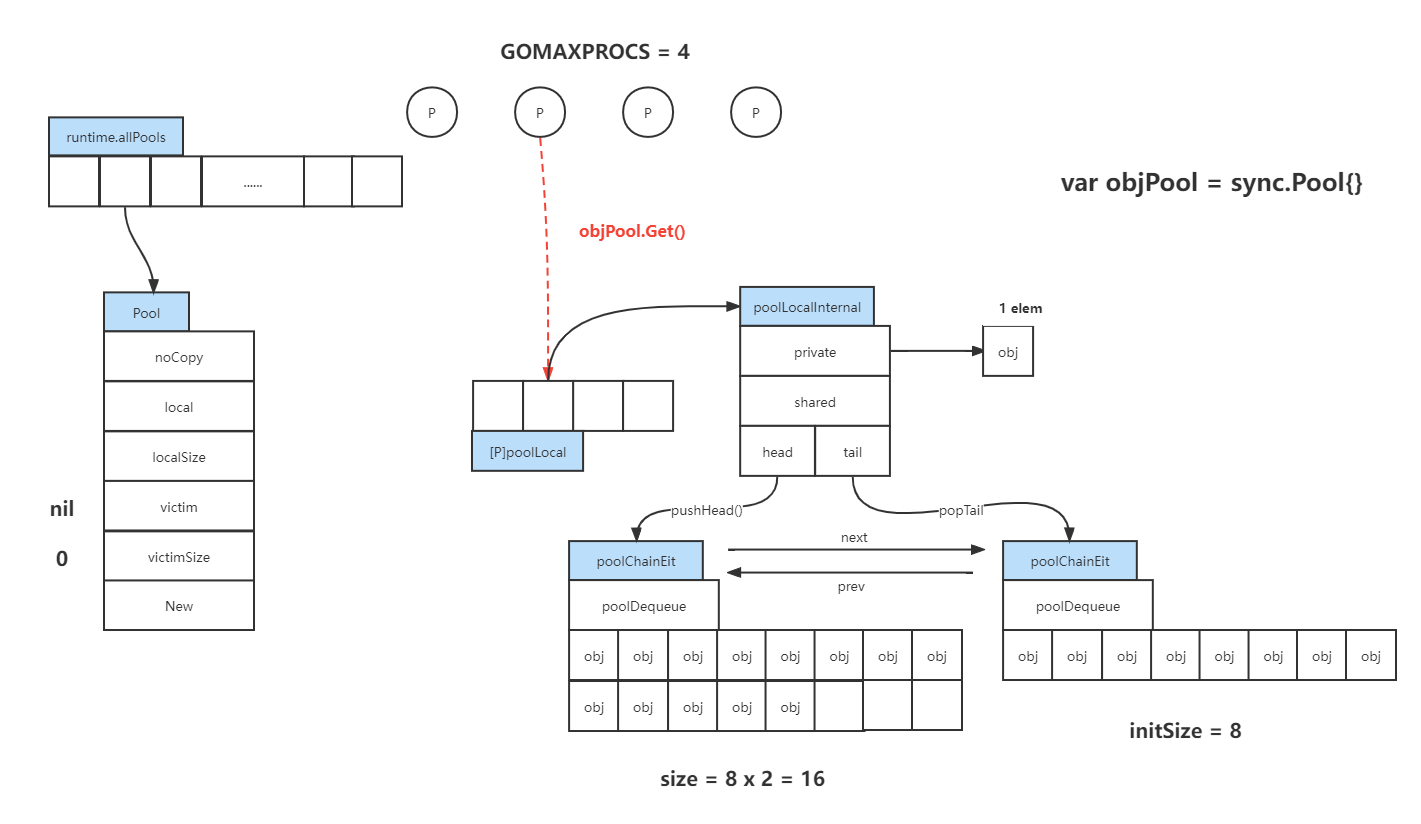
可以从右上角开始看。我们在应用层写了一段代码,其实就是在底层生成了一个 Pool 对象,并且一定会被追加到全局对象数组 runtime.allPools 中去。这个流程也告诉了我们,在写应用代码的时候不能不停地去生成 sync.Pool,因为底层会不断做追加操作并且会加锁。如果代码这么来写就很容易导致性能问题。
左边部分:
-
可以看到 Pool 结构中第一个叫做 noCopy,在 runtime 中有很多结构体都有这个字段,意思是不要对这个结构体做拷贝操作,因为拷贝后可能会产生 BUG,比如拷贝数据的同时也拷贝了里面的锁或者做了浅拷贝就会在删除对象时出问题。
-
local 和 localSize 是一对。local 代表的是一个 Pool 数组对象,localSize 其实也就是图最上方 P 的数量。正常情况下,GOMAXPROCS = 4,那么 localSize 大小就是 4,也就是长度为 4 的 Pool 数组对象。
-
victim 是为了做优化加入的特殊东西,也和 victimSize 是一对。具体含义之后再分析。
-
New 是我们在初始化 sync.Pool 的时候提供的 New 函数。
右间部分:
- 我们假设 GOMAXPROCS = 4,也就会生成大小为 4 的数组,每个元素都是 poolLocal。其中任意一个,它的结构是 poolLocalInternal,它有分了两个级别 private 和 shared。private 可以理解为 CPU cache 之类的,并且如果要从这里面拿数据,都是拿的第一个,并且只能存放一个元素。在查找时如果 private 为空,那么就需要找 shared 的链表。在添加数据时,如果 private 满了,就会往shared 里面写。
- shared 链表设计地比较神奇,它是一个无锁链表。当我们想插入数据时,就会通过 pushHead 函数往 poolChainElt 对象的数组中去存放。这个 poolChainElt 对象在生成的时候也非常神奇,最初它只生成了 8 大小的数组。如果 8 大小的数组放不下了,就会生成第二个数组,也就是 16 大小的数组;并且之后放不下了,扩容的规律是依次翻倍,但最终也有一个限制。
中间部分:
- 最后,如果整个 objPool.Get 操作未成功的话,还会去之前说的 victim 中去找。
- 如果还是找不到,就会去其他链表的 shared 中去找。
- 可以看到这个 shared 其实是在所有 P 之间共享的。不考虑 victim,比如这副图中 private 可以当做 L1 cache,shared 是 L2 cache,而其他的 shared 可以当做 L3 cache。
总结一下,sync.Pool 的代码逻辑也是和缓存的机制非常类似,都是多级缓存结构。
当 sync.Once 发生 GC 时,sync.Pool 的代码逻辑有有怎样的变化呢?下期文章继续分析。
最后,我们学习了一些 Go 语言的并发结构,如果想写一些复杂逻辑,学会一些扎实的理论和精巧的设计能够帮助我们做得更好,这里有几本推荐的书籍:

第一本书籍较薄,也是比较实用的。
第二本也是小册子,不过是偏理论些。如果要写一些高性能无锁算法书中讲的可能用得到。比如理解 atomic 操作和普通内存操作,以及如何保证二者之间的完备顺序不会出现并发的 BUG。
第三本是前 IBM 工程师写的开源书,如果想在并发中更深入可以看看。里面有大量的理论,基本上常见 60% 的并发知识都在其中。
OK,下期继续讲解一些并发场景以及并发内置数据结构。