一个优质的程序、优秀的设计不是凭空产生的,而是经过由简至精,不断迭代产生出来的。在上期文章中,我们了解了 Go 语言中的信号量 semaphore 和互斥锁 sync.Mutex,在此基础上我们还可以实现更加复杂的锁。
sync.RWMutex
读写锁 (sync.RWMutex),可以来看下它的数据结构和运作逻辑:
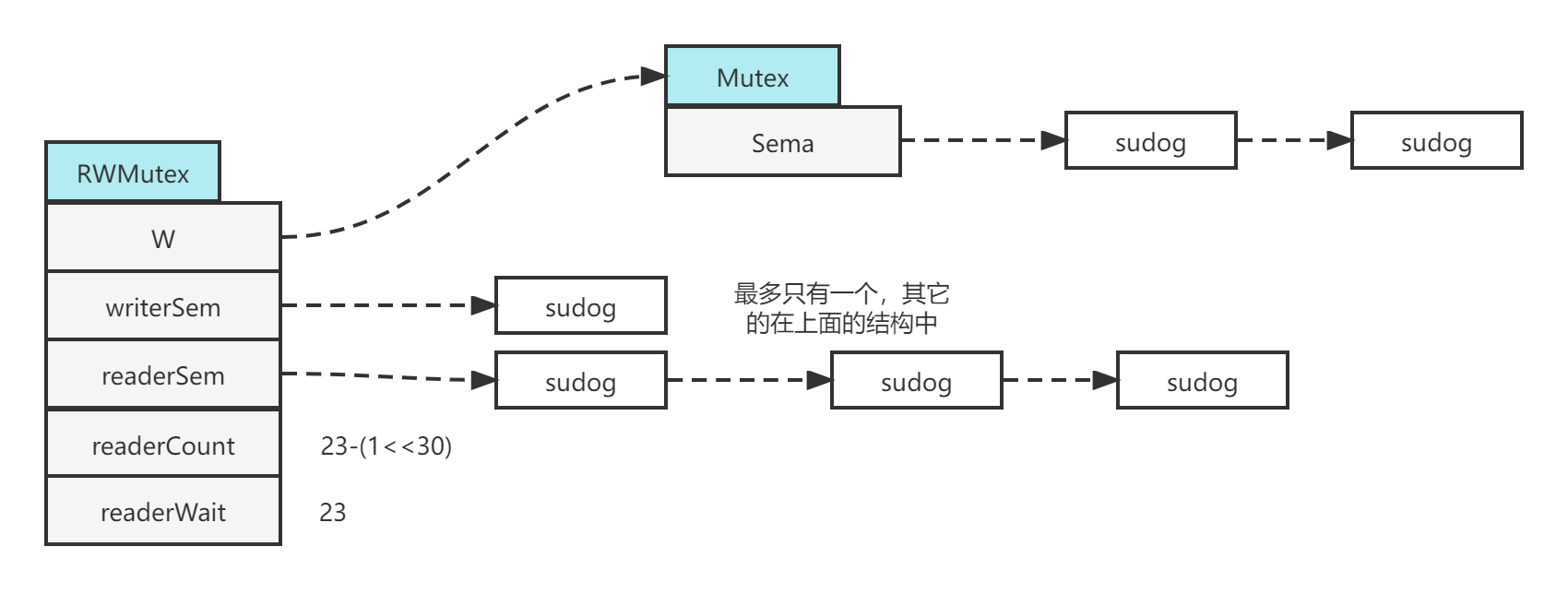
可以看到它的第一个结构叫做 w 其实就是互斥锁 sync.Mutex。在这里的作用是为了挡住大部分写操作的 Goroutine,只让第一个进来的能够和其他的读操作的 Goroutine 去做竞争。
现在有一个写 Goroutine writer 进来了,如果还有其他 reader 在做操作,就会把这个进入的挂载在 writerSem 后面的 sudog。如果后面来了新的 writer,前面的 writer 还没有退出的话,那么新的 writer 就需要挂载在之前的互斥锁 sync.Mutex 上的 sudog 后面。同样的 writer 和 reader 也会在不同阶段去做些竞争和唤醒的操作。
一旦有一个 writer 进入并且调用了 lock,那么就会在 writerSem 后面挂载一个阻塞的 sudog,并且把 readerCount 减去一个最大的值,即图中 1 左移 30 的值,最终让 readerCount 变为负数。当 readerCount 变为负数时,reader 在执行 Runlcok 的操作以后,会发现当前已经变为特殊模式了,所以就会后来进来新来的 reader,这些新的 reader 会去调用 Rlock,那么就会挂载在 readerSem 队列中。readerSem 其实也是一个信号量,最终会对应一个等待队列,并且最后的结构 readerWait 的数量其实是和这个等待队列的数量是对应的。
小结一下,一般正常的操作流程是这样的:如果没有 writer 在等待,那么 reader 可以直接去修改 readerCount。readerCount属于正值,readerWait 为 0。一旦有个 writer 阻塞了,那么 readerCount 变为负,readerWait 数量就和 readerSem 队列中等待的数量一致。最终之前来的 reader 它们都执行完之后,会发现 readerCount 是个特殊的值,然后就会把 writer 唤醒,让 writer 去执行它的逻辑。
sync.Map
并发安全的 map 结构 sync.Map,这个结构稍微复杂,不过一点点拆解地去理解,就不是那么困难了。
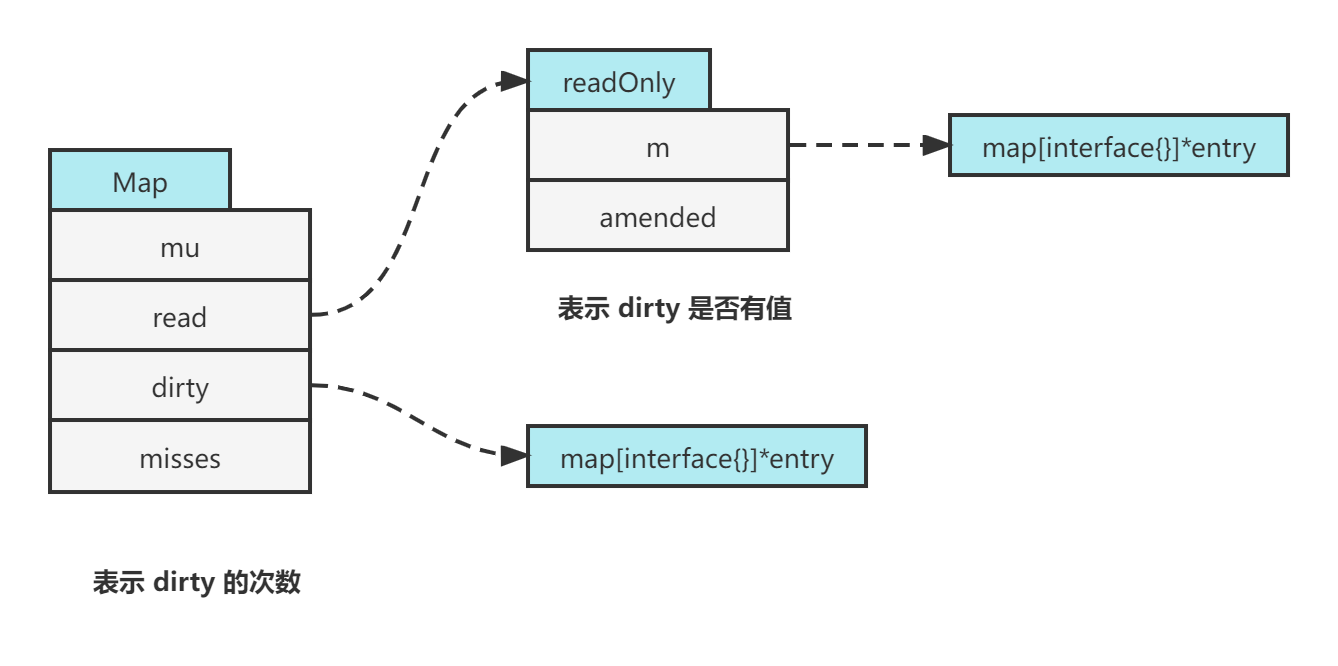
在 sync.Map 结构中,mu 表示 Mutex,可以不用在意。其余分为了两个结构一个是 read,一个是dirty,还有一个计数器 misses。
read 表示优先去读的 map,即图中的 m。amended 结构表示当前 dirty 结构中是否有 read 没有包含的数据,如果 amended 是 true,那么就表示 dirty 中是有值的。而 misses 会在 read 没有值的情况下去 dirty 中去找值,并且每次发生这种情况的时候都需要对这个 misses + 1。一旦这个 misses 加到了 dirty 的长度大小时,说明当前需要将 dirty 和 read 的值做交换,即把 dirty 变为 read,把 dirty 置为 nil。
这里有个模拟的代码片段:
1m = sync.Map{}
2m.Store("x", 1)
3m.Store("y", 2)
4m.Load("z")
5m.Load("x")
6m.Load("y")
7m.Delete("x")
8m.Store("z", 3)
9m.Store("x", 10)
-
第一步初始化 sync.Map,这时候 misses 中的值为 0,amended 是 false,并且 m 和 dirty 两个 map 中没有值
-
第二步向其中存入一对键值 “x” 为 1,即 dirty 中的 map 存入了 key 为 “x”,val 为 1 的值。由于 dirty 有了 read 中没有的值,所以 amended 为 true。
-
第三步继续存入一对键值,dirty 会有了第二组值,key 为 “y”, val 为 1。
-
第四步读取 “z”,这个键既不在 read 也不再 dirty 中,所以不会去修改 misses。
-
第五步读取 “x”,是去读取 read 中的键,而这个键存放在 dirty 中,所以需要把 misses 改为 + 1,说明在读期间发生了一次 miss。
-
第六步继续读取 “y”,这个键也存放在 dirty中,misses 继续 + 1。这时候因为 misses 的大小和 dirty 的长度一样,dirty 就会和 read 交换,read 存放 dirty 中的值,misses 还原为 0,dirty 置为空。
-
第七步删除键"x"中的值,会将 read 中的 map 存放的键 “x” 做一个修改而不会真正地删除,而是置为 的值。
-
第八步继续存键值对 “z” : 3,底层会将 read 中所有键值对都拷贝到 dirty 中(被修改为 expunged 的键值对不会被拷贝),并且会把新的值写入 dirty 中。
-
第九步再存一对键值对 “x”: 10,会将 read 中已有的键 “x” 的值修改为 10,向 dirty 中存入键 key 为 “x”,值 val 为 10。这里有点神奇,read 和 dirty 内部都有相同的键 key,不过它们的 val 值都是指向的同一个地方
整个 read 结构中读和写都是不需要加锁的。dirty 中的写操作要比正常的 map 操作多了非常多的流程,而且要加锁。所以说 sync.Map 是在写少读多的场景下比我们标准的 map 速度要快很多的。
sync.Waitgroup
最后一个并发结构,比较容易理解,关键只有一个 state 字段,还是来看下图:
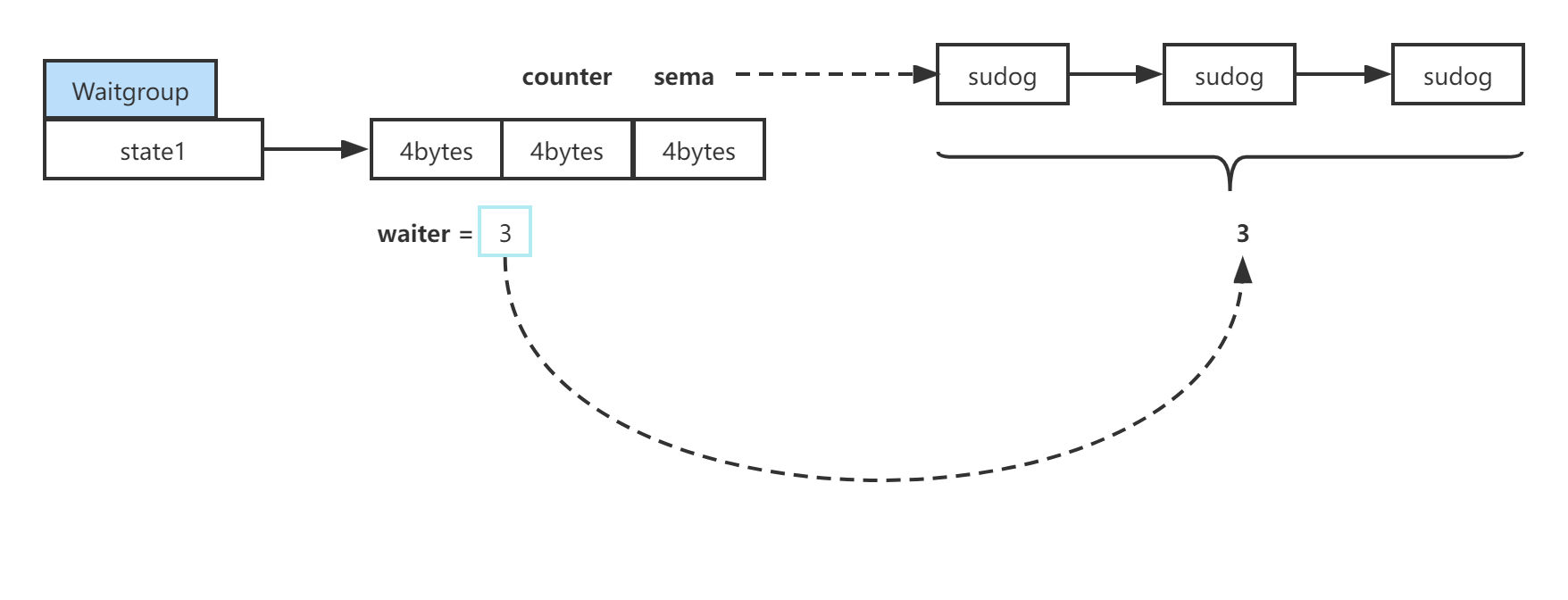
它将 state 分为 4 bytes 一个组,中间是个 counter 计数器,waiter 是指我的应用代码在多少个 Goroutine 里面执行了 WG.Wait,如果有一个就 + 1(平时常见的也是1)。右边是信号量 sema 结构,一旦有程序发生了阻塞,wait 的信号量就会挂载在这个后面,成为一个链表。最后,如果 counter 减少到 0 时,就会唤醒所有 sema 上阻塞的 sudog。
OK,以上就将 Go 语言中大部分 sync 库中数据结构都简单学习了一遍,串起来了。下期文章将会讲解一些并发编程模式下的例子,敬请期待。