今天聊一聊 Go 语言中的内存模型,这部分内容在对于利用 sync 库在进行应用开发中用处不大,不过我们在面试过程中可能会遇到,这里做个记录。
我们日常的开发中,只要知道使用显示同步就可以保证正确性。也就是说只要发生了并发的情况,那么一定要显示地使用同步手段。显示同步手段,通常是指 channel 或者锁。并且,能够用 channel 和锁的情况下,基本上,只要没有 race 出现,就能够保障程序的正确性。
但我们在开发中有时候会给别人提供偏底层的库,那么需要对底层有了解才能做得出来。因此就遇到了 Memory Model 内存模型。
Memory Model
在具体了解之前,我们先要了解目前的 CPU 架构。现代的 CPU 内部的存储其实都是分级的,比如以下就是个多核 CPU 的典型架构图:
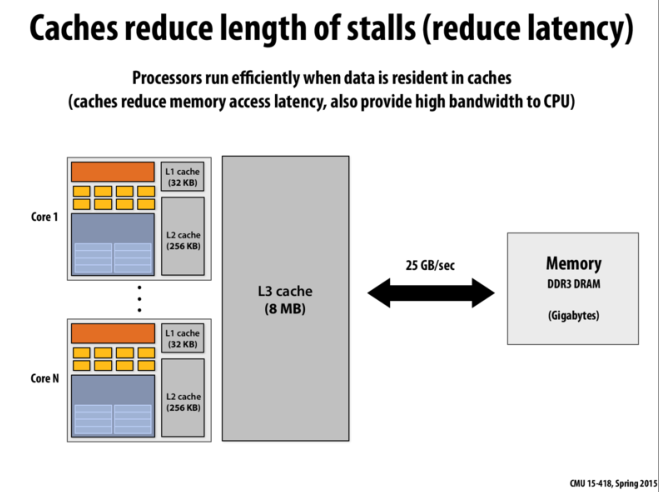
在这个内部,我们可以看到 L1 cache,具体的信息可以通过命令 lscpu 查看到,如下图所示:
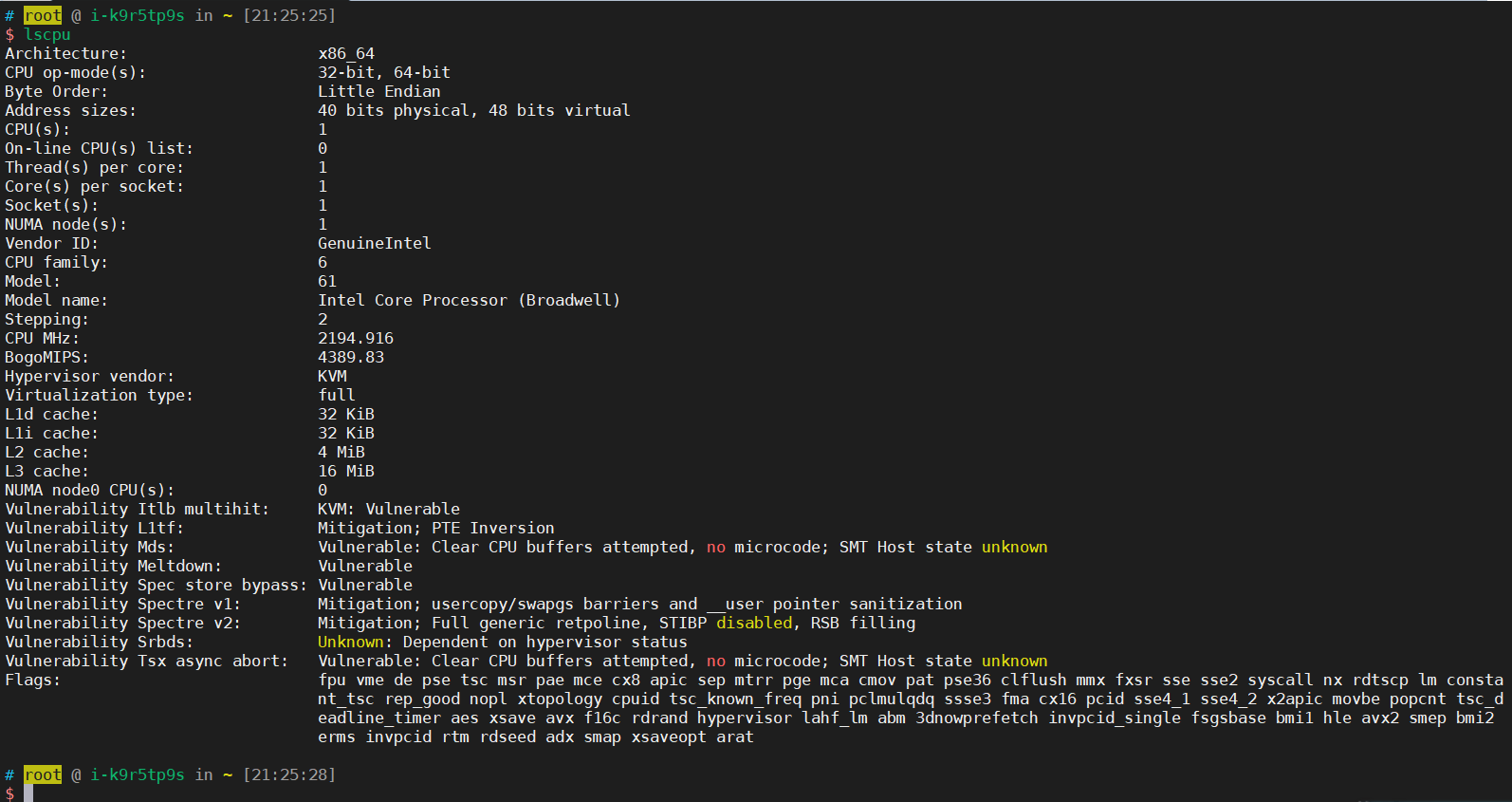
L1 cache 有两种类型: L1 Data cache 和 L1 Structure cache。我们平时在编程中经常遇到的就是 L1 Data cache,也就是在修改内存中变量的时候,一定需要从内存中一级一级地把它加载到 L3 → L2 → L1→ core 最终才能让 CPU 核心去处理数据。
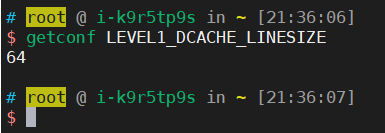
L1 cache 又会被划分为多个更细粒度的 cache line,每个 cache line 的大小为 64 bytes。这就是我们为什么在程序中经常会看到,有些数据结构会在其最后不足的情况下补足为 64 字节或 128 字节,都是有可能发生的。我们在 Linux 中也可以再动动手去做些实践尝试一下这个命令:getconf LEVEL1_DCACHE_LINESIZE,可以看到 Data cache 的 cache line 长度,也就是 64 个字节。
这里还有两段 Go 语言 Runtime 源码中 cacheline pad 的代码,更加有助于我们理解:
1var work struct {
2 full lfstack // lock-free list of full blocks workbuf
3 empty lfstack // lock-free list of empty blocks workbuf
4 pad0 cpu.CacheLinePad // prevents false-sharing between full/empty and nproc/nwait
5}
pad0 能够补齐 struct 来避免一些 false-sharing 情况。这里结构较为简单后面再来说明。
现代计算机多核心能够提高效率,但多核心也给我们带来了一些问题:
- 单变量的并发操作也必须使用同步手段,比如 atomic。
- 全局视角下观察到的多变量读写的顺序可能会乱序。
也就是说,只要有全局的或共享的变量,那么我们在操作它们的时候,一定要使用同步手段,或者至少要需要是 atomic 的操作。另一方面,多变量的读写顺序在多核心的情况下有可能会被打乱。
先来看看单变量的原子读和写操作。为什么 atomic 可以保证当前进行了写操作,其他地方能够读取到?其实 atomic 也就是 CPU 提供的一些原始的指令。其内部的实现是通过多核心使用 Mesi 协议来保证的正确性,这里有张图:
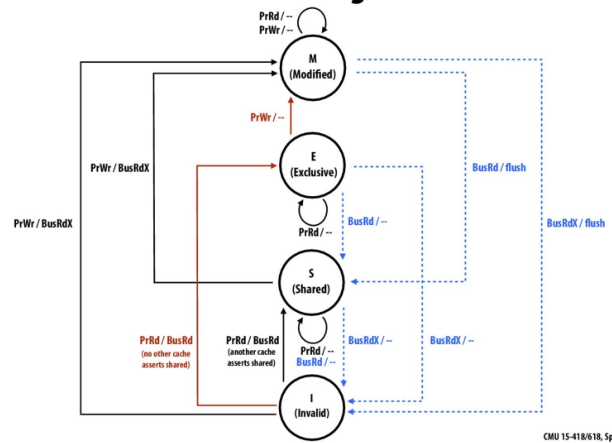
Mesi 协议其实是简化过的描述,事实上不同的 CPU 实现的方式是不一样的,比如 Intel 和 AMD 实现的是不一样的。不过基本的 Mesi 协议可以这样理解:
- 有四种状态分别是:M(Modified) 修改、E(Exclusive) 独占、S(Shared) 共享 和 I(Invalid) 失效;
- 多核在共享一个变量的时候会切换到 S 状态;
- 处于 I 状态,缓存中的数据已经失效了,如果想要对其进行读或写,必须从别的地方去拿。
这些状态如何转换有个表格:
| p0 | p1 | p2 | p3 | |
|---|---|---|---|---|
| Initial state | I | I | I | I |
| p0 reads X | E | I | I | I |
| p1 reads X | S | S | I | I |
| p2 reads X | S | S | S | I |
| p3 writes X | I | I | I | M |
| p0 readx X | S | I | I | S |
- 最初的状态,里面每个核心对应的状态都是 Invalid;
- 当核心 p0 通过 atomic 去读取全局变量 X 时,经过了 Mesi 协议,因此将 p0 中的 cache line 变为 Exclusive 独占状态(如果其他核心想要读取 X 变量就会修改当前的状态);
- 如果核心 p1 也需要读取 X,就会把之前 p0 的 cache line 修改为 Shared 的状态,并且 p0 和 p1 都持有了 X 其 cache line 状态都是 Shared 的状态;
- 这时候如果核心 p2 也读了 X,过程和上一个类似,也会变为 S 状态;
- 核心 p3 的的操作不一样了,它需要去写入 X,也是通过 atomic。就会把 X 这个变量加载到自己的 cache line 中,并且修改 X 的值,当前它的 cache line 的状态为 Modified,并且把其他所有核心为 S 状态的都修改为 Invalid。也就是说在它们之后需要用 X 的话就从别的地方去拿这个变量,现在的 X 已经不合法了;
- 然后,核心 p0 又要读 X,就会和核心 p3 一起都变为 Shared 状态。
另外,国外顶尖大学 CMU 有一门课专门来讲了并发计算机的架构,非常好,建议感兴趣的读者可以自行去了解。
OK,下期继续讲解内存模型,看一看多核结构下还存在哪些问题,已经有什么样的解决方案。
参考资料
[1] A Modern Multi-Core Processor
http://15418.courses.cs.cmu.edu/spring2015/lecture/basicarch/slide_042
[2] MESI Cache Coherency Protocol
https://www.scss.tcd.ie/Jeremy.Jones/VivioJS/caches/MESIHelp.htm