在 Go 语言的内存模型文档中会专门对 Happen-before 进行描述,网上也有很多分析文章对这个概念进行了阐述,但存在一些场景的误区。那么 Happen-before 到底是什么?有什么特征?在此之前我们先来回顾一下 goroutine 的三个基本特征。
Goroutine
在 Go 语言中,同一个 goroutine 内的逻辑有依赖的语句执行,满足顺序关系。比如我在一个 goroutine 里执行了一个很简单的函数:
1func printA() {
2 a = 1
3 println(a)
4}
只要在其他 goroutine 中没有对这个 a 做修改,那么我们预期和实际的程序运行结果一定是 1,不会是 a=0 的情况。这个过程是个基本的逻辑保证,如果说保证不了的话,相当于我们的代码结果没有办法去做预测了。所以从直觉上我们就能理解这句话。
另一个特征是说:编译器/CPU 可能对同一个 goroutine 中的语句执行进行打乱,以提高性能,但不能破坏其应用原有的逻辑。比如有两个线程,分别会修改 x 和 y 变量的值,第一个线程中修改了 x 的值,并且载入了变量 y。虽然没有修改 y,但提前预加载提高了性能。
最后个特征,不同的 goroutine 观察到的共享变量的修改顺序可能不一样。其实也就是我们在上期文章中提到的内存重排。在 Go 语言中,我们说到同步的时候是指在 goroutine 之间发生的操作,其实在其他语言中是和线程的概念和操作是一样的。说到底,goroutine 在运行的时候就是在线程上去执行的。
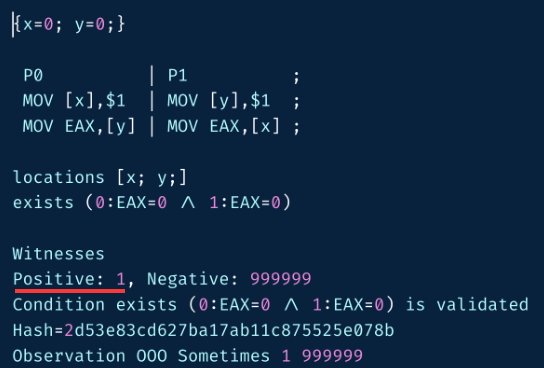
上期文章我们还知道了可以通过使用 Litmus 工具测试和观察内存重排,不仅如此,我们在用 Go 语言进行并发编程的时候,如果写的代码不够严谨,在线上产生错误的可能性有 1/100w,那在找 bug 的时候真的是很要命的。
Happen-before
在官方的并发模型文档中,Happen-before 说的是什么呢?
第一个特征:Init 函数一定在 main.main 之前执行:
A pkg importt B pkg,那么 B pkg 的 init 函数一定在 A pkg 的 init 函数之前执行。
这句话有点像废话文学?记得我上次导入包的时候,还是上一次。其实我们如果能够看到初始化代码的话,基本上能够知道什么时候去调用哪些模块的函数。
第二个特征,Goroutine 的创建:
Goroutine 的创建(creation)一定先入 goroutine 的执行(execution)
这句话也是很好理解的,如果我们的 goroutine 创建到一半的时候就开始执行了,那么其中的状态就没办法保证了。
第三个特征,Goroutine 的结束:
在没有显式同步的情况下,goroutine 的结束没有任何保证,可能被执行,也可能不被执行
这里的意思是说,比如我们写了一个 main 函数,最后打印了一个 “Hello World”,不过在打印函数 println 之前,又写了一个 go func 目的是想打印一个别的字符串。显然,go func 中的代码没有被执行,整个进程还退出了。如果想要这个 go func 一定被执行到,那么就需要显式地去执行诸如 wg.Add, wg.Wait 之类的东西。这个特征也是比较符合人的直觉的。
第四个特征,Channel 收/发:
A send on a channel happens before the corresponding receive from that channel completes.
有点像玩文字游戏了呢。也就是说,如果我向 channel 发送值的时候,这个操作一定是在 channel 接收操作之前完成的。这里有一段代码例子:
1var c = make(chan int, 10)
2var a string
3
4func f() {
5 a = "hello, world"
6 c <- 0
7}
8
9func main() {
10 go f()
11 <- c
12 print(a)
13}
在 main 主函数中启动一个 f 函数的 goroutine。在这个 goroutine 中,对全局变量 a 赋予一个值,再向 channel c 发送了 0 值,然后在 main 函数中接收这个值。也就是说 channel c 的接收一定是在 channel c 发送完成之后才接收到的。channel 在接收前发送了,说明先进入了 f 函数,并且 a 也被赋予了值。因此最终,print 一定能够打印出 “hello, world” 而不是别的内容。
在实际代码中,我们不仅可以用 channel 来保证先后顺序性,还可以通过加锁的方式来实现。这里有个比较难的思考题,为什么我们可以通过互斥量来实现锁?因为互斥量里面也是自己的 state,和用户定义的 state 没什么关系。lock 中的变量又为什么没有被内存重排呢?这个问题还需要再深入学习才能了解了,这就作者也还在研究中。
如果 f 函数中,c 不是一个 channel 而是一个变量,进行了变量赋值,那么就可能发生内存重排。这是因为 channel 操作是同步的,这个官方给出的约束告诉我们用了 channel 就不会发生内存重排。
第五个特征,Channel 收/发:
The closing of a channel happens before a receive that returns a zero value because the channel is closed.
也是有的像句绕口令,其实案例代码改动不大:
1var c = make(chan int, 10)
2var a string
3
4func f() {
5 a = "hello, world"
6 close(c) // modified
7}
8
9func main() {
10 go f()
11 <- c
12 print(a)
13}
这里可以看到其实只是把 f 函数中向 channel c 发送值变为了关闭 channel c 。最终得到的结果其实是一样的,因为关闭操作里面是有唤醒操作的。在之前的分析文章中,我们看过 channel 的源码就知道,关闭 channel 操作的时候会把所有阻塞在
第六个特征,依然是Channel 收/发:
A receive from an unbuffered channel happens before the send on that channel completes.
同样的拗口+微调代码
1var c = make(chan int) // modified
2var a string
3
4func f() {
5 a = "hello, world"
6 <-c // modified
7}
8
9func main() {
10 go f()
11 c <- 0 // modified
12 print(a)
13}
这里是说没有 buffer 的channel,receive 操作先于 send 操作执行完成,那么这里也可以保证打印出 “hello,world”
第七个特征,Lock:
For any sync.Mutex or sync.RWMutex variable I and n<m, call n of I.Unlock() happens before call m of I.Lock() returns.
这里的意思说是 Unlock 一定是先于 Lock 函数返回前执行完。也是很符合直觉的东西,但从文字表达上看起来有点拗口。
最后,第八个特征,Once:
A single call of f() from once.Do(f) happens (returns) before any call of once.Do(f) returns.
在 once.Do 返回之前一定能够保证我的函数初始化执行完了。当然如果发生了 panic ,它也当成是执行完成了。
小结
说了那么多,Happen-before 到底是什么呢?
本质上其实是在用户不了解底层的 False sharing、内存重排,不知道 memory barrier 的概念和具体实现的前提下,依然能够按照官方所提供的 happen-before 的文档来编写正确的并发程序,并且有个文档可以参考。
对于我们处于应用层开发的程序员,自己一个人直接去看底层的 memory barrier 的话,基本上是看不懂的。
还有一些更深入的底层知识,待笔者去深入了解后再来分析,先做个标记,
如:acquire、release、sequential consistency、Lock-Free、Wait-free 等等。