上期我们说到了 Middleware 可实现洋葱模式,将一些前置或后置的自定义代码插入到业务逻辑之前,并且便于修改。这期文章继续来聊聊常见 Web 框架中的组件。
Router
本质上,路由(Router)就是从字符串匹配到用户函数的过程。这里有两段示例代码:
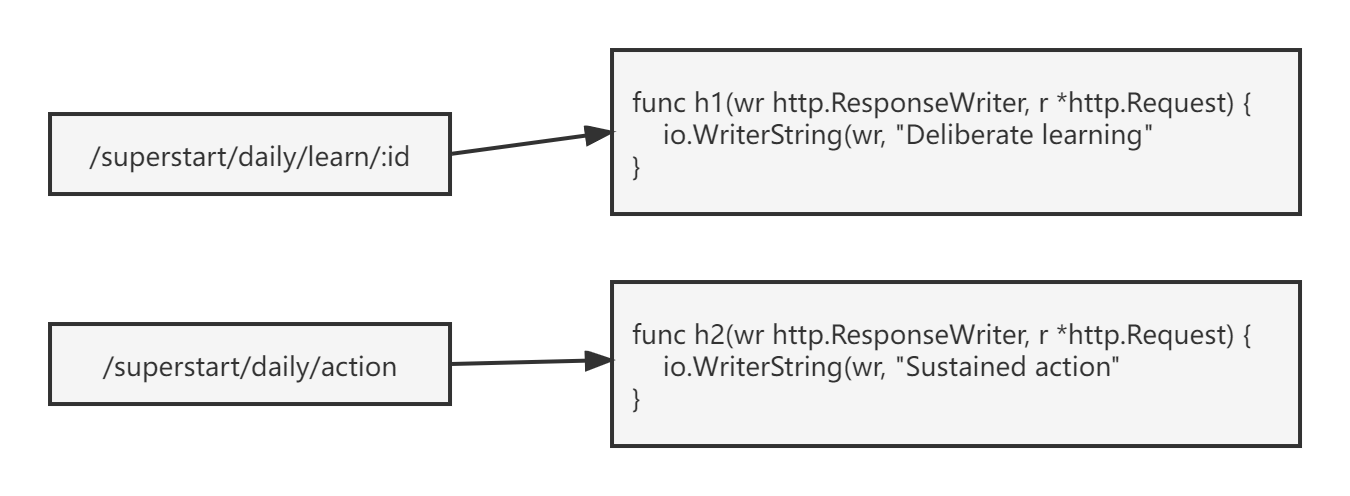
这里用到的是 http 标准库的签名,所以参数类型为 http.responseWriter,和 http.Request。
左边的字符串并不是单独的一个字符串。我们知道在 Rest ful 风格的路由中,很多时候可以带一些参数,比如上方路由有个 id 参数,就可以在用户函数 h1 中的 http.Request 中的路由中解析出来。但我们很多时候知道怎么用,却不知道如何自己来实现这种带参数的实现的,这时候就需要用到一个树结构。
在了解这个树结构之前,我们需要先知道什么是字典树(trie),这里有一幅图:
- 单个节点代表一个字母。
- 如果需要对字符串进行匹配,只要从根节点开始依次匹配即可。
我们可以从这个字典树发现几个单词:比如中间的 OK,右边的 OUT,左边略微复杂的 ONLINE。如果我们需要做一些文本匹配的工作,用到字典树是不错的方式。
但字典树的设计比较浪费空间,有时候我们只是需要存一个字母,但其实开辟了很多空间,这个在路由当中好比有多个层级 /XXX。而如果还想要做字典树的查询,无疑时间上开销还是略大,因为在树的节点之间跳转,一般还是要经过指针的,而经过指针意味着它的内存的局部性不那么好,所以匹配起来可能会比较慢。
Radix Tree
在此基础上,我们可以再了解一下 Radix Tree。

Radix Tree 一般叫做奇数树或放射树,也有叫压缩前缀树。它本身是经过空间优化的字典树。在它里面会把一些子节点的公共的内容合并到父节点里面去,也就意味着单个节点不只存单个字母。
然后来看看 Radix Tree 的几个特征:
- 同一个 URI 在 HTTP 规范中会有多个方法
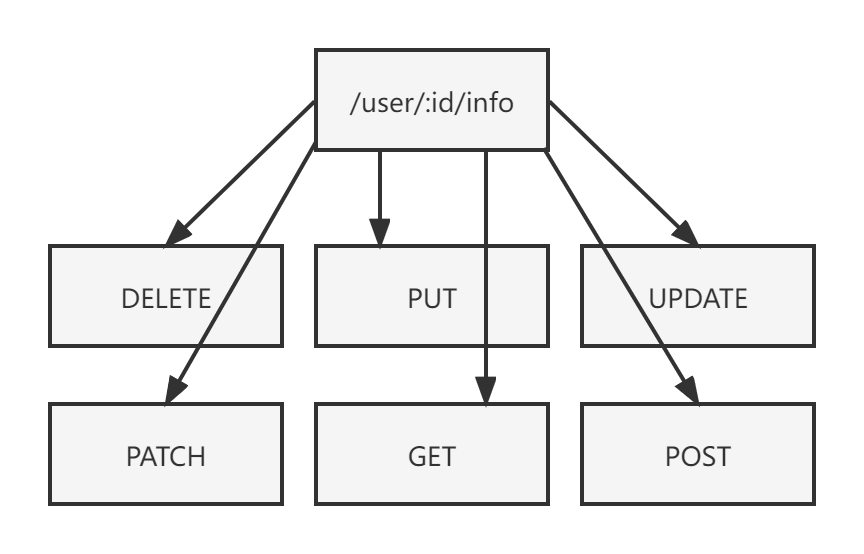
在我们 HTTP 的 Router 实现里,其实不止有一颗 Radix Tree。我们知道,在同一个路由字符串上,可以设置多种操作的。像这里的 Rest ful API 不仅有常见的 GET、POST 方法,还有 DELETE、PUT、UPDATE、PATCH 等方法,并且每一个方法其实都对应一颗 Radix Tree,大概的样子是这样的:
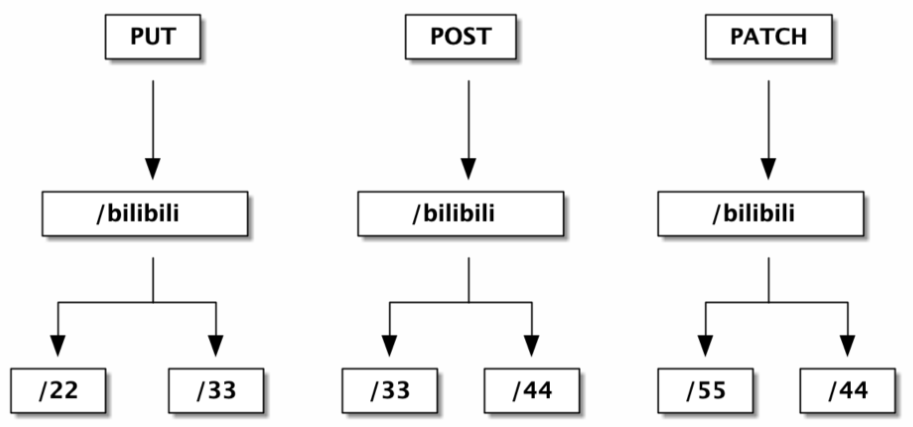
可能我们实际写的例子类似上面,有三种方法 PUT、POST 和 PATCH。在 PUT 下面有这样一个前缀树 /bilibili 然后接 /22 和 /33,在 POST 下面也有相同前缀树 /bilibili 然后接 /33 和 /44,PATCH 类似。这种实现方式是可以的,因为每一个方法的树都是和其他方法彼此独立的。
HttpRouter
接下来我们来看看比较具体的实现是怎样的,来看看它的一些概念和它是怎样去建立我们在前面提到的 Radix Tree 的。
首先还是来理解一些概念:
- node:httprouter 树中的节点。
- nType:是指 node type,其中有几种枚举值:static 非根节点的普通字符串节点,root 根节点,param(wildcard) 参数节点,catchAll 通配符节点。
- path:到达节点时,所经过的字符串路径,比如:
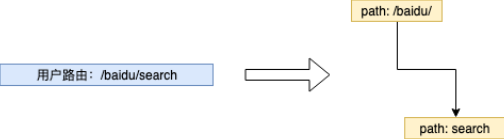
- indices:子节点索引。这是 index 的附属形式,表示的是当子节点未非参数类型时,即本节点的 wildChild 为 false 时,会将每个子节点的首字母放在该索引数组。)—说的是数组,实际上是个 string)
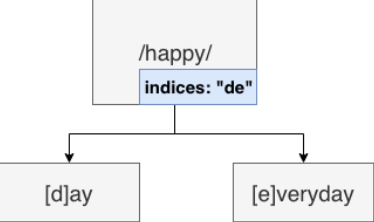
indices 其实就是所有子节点的首字母集合,并用字符串连接起来。
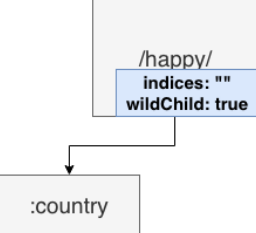
如果子节点未参数节点时,indices 应该是个空字符串,同时还会将另一个参数 wildChild 标记位 true。
- wildChild:如果一个节点的子节点中有 param(wildcard)节点,那么该节点的wildChild 字段即为 true。
- catchALL:以 * 结尾的路由,即为 catchAll。在静态文件服务上,catchAll 用的比较多。后面的部分一般用来描述文件路径。如果:/software/downloads/monodraw-latest.dmg。
Radix Tree 的构造过程
来看一下多条路由在插入到整个 Radix Tree 的时候,树的维护过程。
首先,第一条路由插入 /marketplace_listing/plans/

第一条路由全是字符串,整个树也没有节点,也不需要做节点分裂之类的操作,只需要把所有内容插入到根节点就 OK 了。wildChild 为 false 是因为没有子节点。nType 表明是 root 根节点。indices 表示子节点首字母集合,当前是空的。
第二条路由插入 /marketplace_listing/plans/:id/acounts
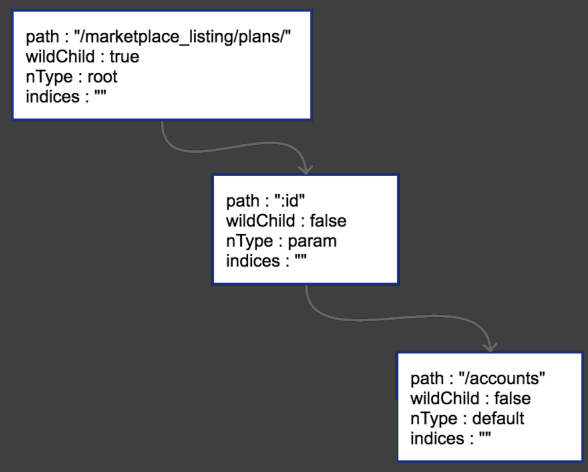
和上一条路由的区别在于 plans 后面跟了别的东西,id 参数 和外加字符串 acounts。因为 id 是个参数节点,所以 nType 为 param。acounts 的类型 nType 为 default。
然后是第三条路由插入时 /search
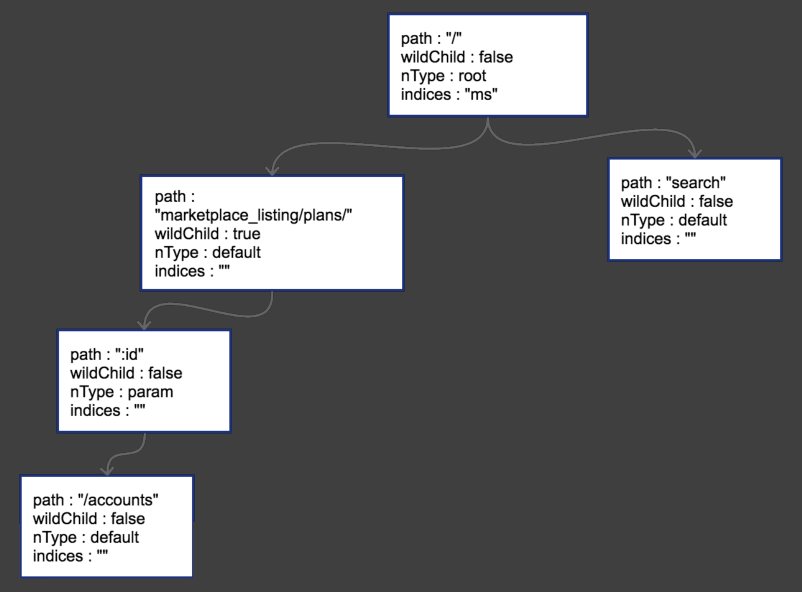
当前插入的路由是和原来的路由 / 发生了冲突,因此在 / 做了个边分裂。左边是原来的路径,右边是插入的新路径。并且由于父节点 / 有了两个字符串节点了,说明需要把它们的首字母提取出来然后放在 indices 里。
之后我们需要做搜索的话,就需要先匹配 path /,然后再匹配 indices 对应的首字母,匹配到了之后继续往下走。
Radix Tree 其实就是字典树的变种,它的主要功能就是做字符串的匹配。如果用户在浏览器中输入了一段路径,那么我们在服务端会拿这个字符串去和树进行匹配。
说到这里,可以发现,Router 的主要功能,就是匹配。
路由冲突
以上我们说的都是可以完美地将字符串插入到树的情况,但实际开发中还是会遇到一些困难,没有这么理想。我们会遇到路由冲突的情况,比如这是一段冲突的路由:
1GET /user/info/:name
2GET /user/:id
而不冲突的路由是这样的:
1GET /user/info/:name
2POSt /user/:id
路由冲突具体的规则如下:
- 在插⼊ wildcard 节点时,⽗节点的 children 数组⾮空且 wildChild 被设置 为 false。例如:GET /user/getAll 和 GET /user/:id/getAddr,或者 GET / user/aaa和 GET /user/:id。
- 在插⼊ wildcard 节点时,⽗节点的 children 数组⾮空且 wildChild 被设置 为 true,但该⽗节点的 wildcard ⼦节点要插⼊的 wildcard 名字不⼀样。 例如: GET /user/:id/info 和 GET /user/:name/info。
- 在插⼊ catchAll 节点时,⽗节点的 children ⾮空。例如: GET /src/abc 和 GET /src/filename,或者 GET /src/:id 和 GET /src/*filename。
- 在插⼊ static 节点时,⽗节点的 wildChild 字段被设置为 true。 在插⼊ static 节点时,⽗节点的 children ⾮空,且⼦节点 nType 为 catchAll。
这么看有点复杂了,一张图能够直观的看出:
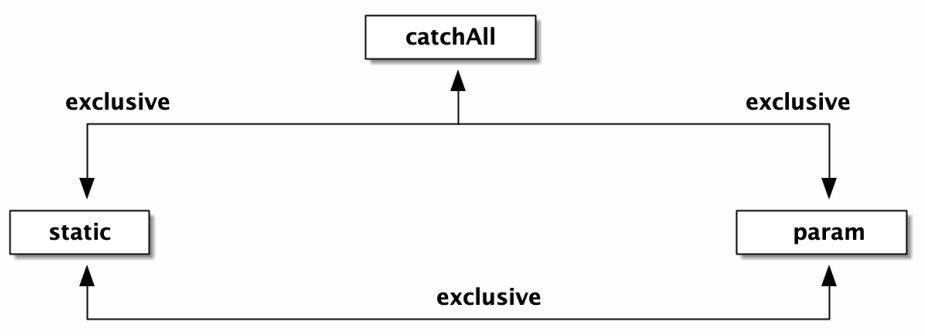
即,同一个节点,其子节点的情况只可能是:
- 一个 wildcard 节点
- 一个 catchAll 节点
- 一个或多个 static 节点
OK,下期文章继续讲解 validator 组件的具体实现!