在我们互联网公司中都会有一类工程师叫做,架构师。他们经常会去参加一些架构师大会。在他们的圈子中也会有一些黑话,我们一般的程序员是听不懂的,因此就需要我们在写代码的同时,去学习一些相关的理论。这些理论只是名词多,其实并不难。
因为 Go 语言主要用在做后端系统,下面说的也是 API 层面的业务分层。
传统分层
在很早的 web 项目中,都是采用的 MVC 的框架模式。
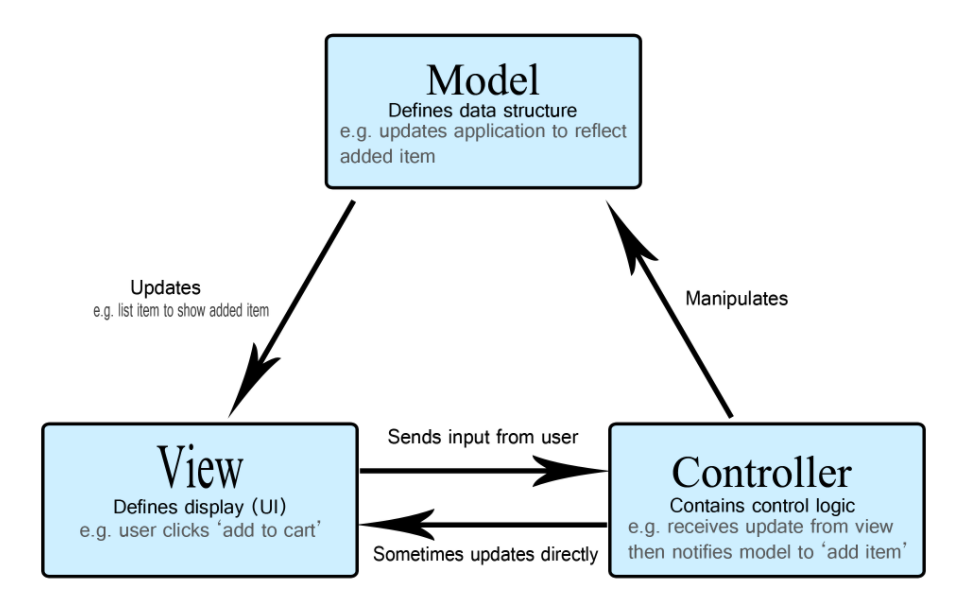
MVC 这种模式在上个世纪 70 年代就已提出,到现在一直在被使用,因此可以说使用 MVC 的 web 项目称得上远古时代。最早的 web 开发用 PHP 的比较多,而 PHP 的架构尤其以 MVC 模式比较多,Model、View、Controller 都是标准化的组件。
但是,存在一个局限性:前后端所有的代码都放在一起的。所以前端可能不那么讲究,就在 PHP 代码中做一套模板引擎,然后直接在在 Vue 里面去写渲染代码;后端的逻辑也很简单,都写在 Controller 里面。情况更糟的是,有些的公司对业务逻辑到底写在哪里还有争议,有的人写在 Model 里。
后来,当前后端分离变成主流共识之后,View 层直接被干掉了。
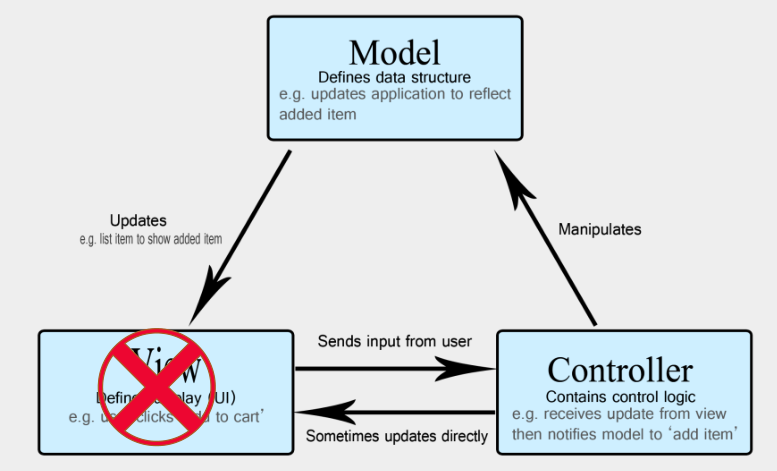
有一个原因在于前端和后端各自都变得比较复杂了,所以前端也要专门去做工程化了,随后有了 Angular、React、Vue 等三大知名的前端框架。
而后端将 View 拆出去以后,只剩 Model 和 Controller,不过项目也开始变得复杂,一个接口就有几千、上万行代码的情况。这种情况,如果将全部代码堆积在 Controller 里面,并且还是按照以前的编程流程,过程式开发的话,整个代码维护起来相当地费劲。
所以,大多数公司的后端会将逻辑越来越复杂的业务,拆分成单独的 logic,如下:
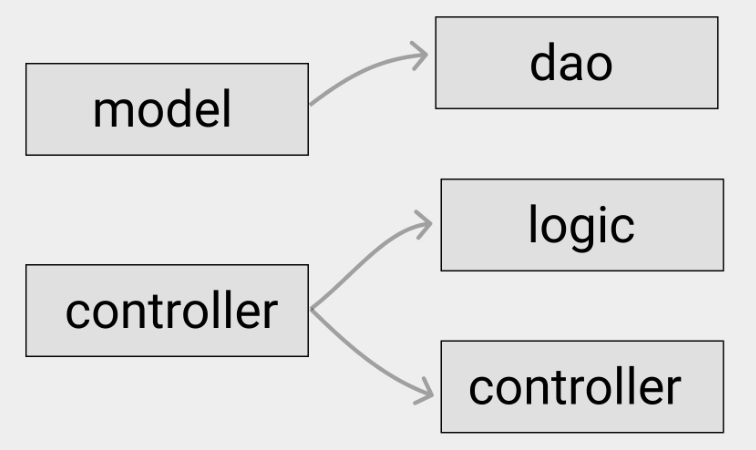
- model 改成了 dao(data access object)。由于 model 很多时候都被当作领域模型来用,看起来里面就应该有一些逻辑。而 dao 就是仅仅作为数据获取的结构体。
- controller 直接被拆分成了两部分,一部分还是叫做 controller,不过功能上更加简单,可能负责的是 API 接口的入口、协议或校验入口等。另一部分 logic ,这个在不同公司有不同的名字,可能叫做 services,都是用来写业务逻辑的。
但是,随着公司的发展,业务逻辑也在逐渐地膨胀,到后面越来越复杂。如果对 拆分后的 controller 没有指导的话,业务代码是很难管理、很难看懂维护的。
后来,DDD (领域驱动设计)社区提出了两种方法:
- 贫血模式。也就是刚刚讲的逻辑,将业务代码都卸载 logic 层内,并且像 Struct、Class 上没有任何逻辑,或只有少量逻辑的代码也写在一起。
- 充血模式。可以往 Struct 和 Class 上去绑定一定的行为,让 domain object 即 entity 有更多逻辑,将原来的业务逻辑从这种改动后剥离出来,还有一些对象校验的也能从业务逻辑中剥离出来。有了这些领域对象之后,再通过聚合来组合 entity 的逻辑,最终组成现有的业务逻辑。
这么说还是有点抽象,来看两个贫血模式代码的例子,摘自书籍《实现领域驱动设计》:

这里的逻辑是想要保存用户的信息,其中有一大堆的参数。可能我现在有一个业务逻辑只是想要更新一下用户所在的城市,那么也要调用 saveCustomer 这个大的函数,并且传入一大堆本来不需要传递的参数。
其中有点糟糕的是,saveCustomer 函数会认为你传入的参数都是有效的,因此会依次把每个字段都做更新,如果其他参数传入的是空,可能就会对其他数据造成影响。
再来看一个实际开发中更可能遇到的场景:

这里的 saveCustomer 函数逻辑将每个字段做了是否为空的校验,如果不为空意味着你想要更新这个字段。
更糟糕的是,业务逻辑被埋没在存储业务之中了,因此这种代码可能导致你在开发过程中“失忆”的,在对某段函数迭代了一段时间以后,本身这个业务逻辑到底要做哪些需求的,完全看不出来了。
DDD 社区提供了一个解决的思路:定义 Customer Repo,代码如下:

首先定义了一个叫做 Customer 的 Repo,然后将之后想要完成的业务需求直接改成了非常具体的函数名字。比如说想要修改用户的地址,就直接加一个功能叫做 relocateTo;如果想要修改电话号码,就添加函数 changeHomeTelephone。这便是整个 Customer Repo 所拥有的的方法集。我们通过阅读当前方法集的名字就能够明白当前的业务需求是什么。
在此基础上,相关的 Repo 实现都相对简单多了:

整个 Repo 的实现比较简单,里面拆分成了几个小的函数。主流程中,根据不同的用例选择执行不同的对象函数,而不是用数据建模,将所有处理集中在同一个函数里。
SOLID
SOLID 是指面向对象设计 5 大重要原则的首字母缩写,当我们设计类和模块时,遵守 SOLID 原则可以让软件更加健壮和稳定。
今天我们重点了解依赖倒置原则 DIP(Dependency Inversin Principle),它的意思是说高层模块不应该依赖低层模块,相反,他们应该依赖抽象类或者接口。这里有一段根据 DIP 原则修改前的代码:
1// business/order.go
2import "dao"
3
4func createOreder(...someData) {
5 dao.SaveOrder(data)
6}
7
8// dao/mysql.go
9func SaveOrder(...data) {
10 // do the mysql job
11}
而使用依赖导致原则修改后的代码,如果最初我们的逻辑是 controller → logic → dao,就能改变为 dao → logic → contorller,代码如下:
1// business/order.go
2// import "dao" 不再依赖 dao 层
3
4var _ OrderRepo = &repoInstance{}
5
6func createOrder(...someData) {
7 repoInstance.SaveOrder(data)
8}
9
10type OrderRepo interface {
11 SaveOrder(...data)
12}
13
14// dao/mysql.go
15func SaveOrder(...data) {
16 // do the mysql job
17}
之前的代码中,业务依赖着 dao,必须导入才能使用。现在我们不让业务依赖具体的某一个存储实现,那么我们就需要把 dao 的操作变为接口。
改造后的代码中,我们定义了一个 repoInstance 来实现接口 OrderRepo,这个接口只有 SaveOrder 的操作。由于 Interface 的定义是和业务代码放在一起的,所以都在同一个文件里,不需要再去导入。并且我们能够在 dao 中实现业务模块中定义的接口。
通过这种改造,我们能够将整个依赖关系从业务到 dao,改变为从 dao 到业务,将逻辑关系反转了。
以下再用一张图来解释我说的话:
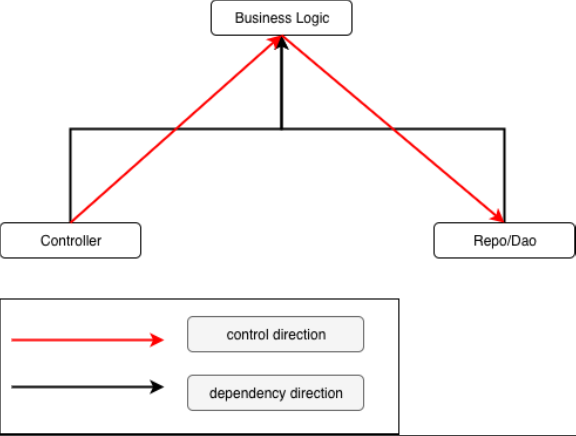
可以看到,无论是入口还是存储层,都会依赖业务逻辑。而如果将业务逻辑放在最上层,意味着业务逻辑可以不依赖任何的库,最终外部任何库的变化都不会导致业务逻辑发生任何变化。
OK,今天讲的只是业务逻辑转化的概念,下期文章继续聊聊各个社区的大佬是如何根据这些原则去写代码的。