读经典《DDIA》-第一章
算是等了好久,终于有机会来读这本书《Designing Data Intensive Applications》,中文名《设计数据密集型应用》,我们一般简称《DDIA》或者猪书(因为书的封面是一头野猪,Hog Riderrrrr~!)。读完这本书第一章,我也想极力向推荐给计算机和互联网行业做后端和服务端的同学。
阅读背景
最初了解这本书是在曹大(曹春晖)的第一堂课上。曹大说自己看了那么多书,只有这一本是最好的,也推荐给大家(当时听完就有点热血沸腾)。后来我还发现,draveness 大佬在它的《程序员可能必读书单推荐(一)》https://draveness.me/books-1/ 中最后一本也提到了此神书。再后来,又去豆瓣看了看,中英文都是 9.7 分:

简单介绍一下,读《DDIA》能够 帮助我们建立一个分布式系统的全局概念,但还需要根据自己所在行业、所处业务和所面对的需求。前面一些章节和 rpc 有关系,中间一些和存储关系比较大,后面将大数据和流式计算。内容比较全,看完就知道分布式系统有哪些问题。
一个人可以走得很快,而一群人能够走得很远。读这本书,其实我是参与了一个小组的 github 读书项目,如果你感兴趣也可以联系我,我们一起参与这次读书之旅。
好,话不多说,开始卷!(以下为我简明扼要摘录的笔记,可以快速浏览)
第一章笔记
为什么要设计
现今很多应用程序都是 数据密集型(data-intensive) 的,而非 计算密集型(compute-intensive) 的。
CPU很少成为这类应用的瓶颈,更大的问题通常来自数据量、数据复杂性、以及数据的变更速度。
数据密集型应用:
- 存储数据
- 缓存
- 索引
- 流处理
- 批处理
看上去平淡无奇是因为数据系统在抽象层面做得非常成功。工程师常常直接拿来用,而不是自己去做开发,因为数据库已经足够完美。
然而现实中还有各种不同的需求:多种缓存,多级搜索。重要的是有必要先弄清楚最适合当前业务的工具和方法。当单个工具已经解决不了我们的问题时,组合使用也有些难度。因此本书在探索如何设计数据密集应用的方法,以实现可靠、可伸缩、可维护的数据系统。
数据系统的思考
按我们的常识,为认为数据库、消息队列、缓存这些工具都是有差异的,但我们还是归类为 数据系统当中。虽然新出现了许多数据存储工具和数据处理工具,但类别之间的界限越来越模糊,比如:数据存储可以作为消息队列(Redis),消息队列带有类似数据库的持久保证(Apache Kafka)。
当单个工具不足以满足所有数据处理和存储需求,就需要将总体工作拆分成一系列能够被单个工具高效完成,并且通过应用代码缝合起来。如缓存(Memcached)和全文搜索(ES)结合将主数据库剥离,由应用代码来让缓存或索引和主数据库保持同步。
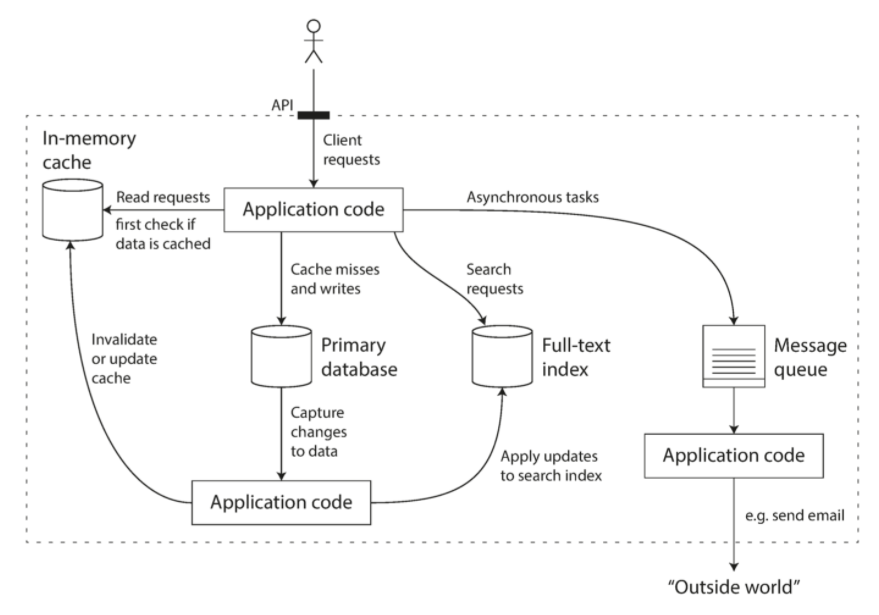
一个可能的组合使用多个组件的数据系统架构
多个工具组合提供服务,服务的接口或应用程序编程接口 API 会向客户隐藏实现细节。
设计 DIA 会遇到问题:系统故障,如何保证数据正确性和完整性?系统退化降级,如何给客户提供始终如一的良好性能。负载增加,如何扩容?什么样的 API 是好的?
影响设计的因素:参与者技能和经验、历史遗留问题、系统路径依赖、交付时限、公司风险容忍度、监管约束。
本书重点讨论:
- 可靠性。在 adversity 中(包括:硬件、软件、人为 故障或错误)仍可以正常工作。
- 可伸缩性。合理应对系统增长(数据量,流量,复杂性)
- 可维护性。不同参与者,在不同生命周期都能高效地在系统上工作(适应新的应用场景)。
可靠性
常见期望:
- 符合用户期望的功能
- 允许出错,还能正常使用软件
- 高负载下,性能不降太多
- 防范未授权和滥用
错误原因——故障 fault,能预料并应对的故障特征——容错 fautl-tolerant 或 人性 resilient
> 注意:失效是系统停止向用户提供服务,有区别。
故障概率不可能降为 0,最好设计容错机制,防止因故障而失效。
反直觉,通过故意出发来触发故障率,是有意义的。如:没有警告随机杀死单个进程。
许多高位漏洞就是由于糟糕的错误设计,通过提高故障自然发生,可以减少失效性。如 Netflix公司的Chaos Monkey
硬件故障
常会想到的硬件故障:硬盘崩溃,内存出错,机房断点,拔错网线。
第一反应,增加单个硬件冗余度。如:磁盘组件 RAID。服务器可能有双路电源和热插拔CPU,数据中心可能有电池和柴油发电机作为后备电源,某个组件挂掉时冗余组件可以立刻接管(岁不完全防止,但简单易懂)
大量使用机器,会相应增加硬件故障。如:云平台实例不可用没有任何警告。因此,设计云平台优先考虑灵活性和弹性,而不是单机可靠性。
硬件冗余+软件容错。如:如果需要重启机器(例如应用操作系统安全补丁),单服务器系统就需要计划停机。而允许机器失效的系统则可以一次修复一个节点,无需整个系统停机。
软件错误
常认为硬件故障随机、相互独立。
另一类错误是内部系统错误,难以预料,因为可能造成更多系统失效:
- 错误输入,服务器崩溃。如:时间错误,Linux 内核挂掉。
- 时空进程占用资源。包括 CPU时间、内存、磁盘空间或网络带宽。
- 系统依赖服务变慢、未响应、返回错误响应
- 级联故障。小组件故障引发另一个和多个组件故障
这些 BUG 潜伏时间长,直到被触发。
软件故障没有速效药,但有许多小办法。如:
- 考虑系统假设和交互
- 彻底测试
- 进程隔离
- 允许进程崩溃并重启
- 测量、监控并分析生产环境中的系统行为
- 系统自检(如消息队列中,进入与发出数量相等),并在出现差异 discrepancy 时报警
人为错误
运维配置错误是服务中断的首要原因,而硬件故障仅占 10%-25%。
尽管人类不可靠,但最好的系统会采用一下组合:
- 最小化犯错设计系统。
- 将容易犯错的地方解耦 decouple。提供功能齐全的生产环境沙箱 sandbox
- 在各个层次进行彻底测试。包括:单元测试、全系统集成测试和手动测试。自动化测试适合边缘场景 cornet case。
- 允许从人为错误中简单快速回复,最大限度减少失效。如:回滚配置变更,分批发布新代码,提供数据重算工具。
- 配置详细和明确的监控。如:性能指标和错误率。
- 管理实践和培训
可靠性的重要
商务应用中错误导致生产力损失(数据报告不完整有法律风险),电商网站中断导致收入和声誉损失。
某些情况,会选择牺牲可靠性来降低开发成本,但要意识到在偷工减料(为后期修修补补甚至大换血做好心理准备)。
可伸缩性的重要
负载增加是服务降级 degradation 的常见原因。如:系统负载已经从一万个并发用户增长到十万个并发用户,或者从一百万增长到一千万。也许现在处理的数据量级要比过去大得多。
负载又可以称为 负载参数(load parameters) 。最佳参数选择取决于系统架构,如:每秒向Web服务器发出的请求、数据库中的读写比率、聊天室中同时活跃的用户数量、缓存命中率等等。除此之外,也许平均情况也很重要,也许瓶颈只是少数极端场景。
一个应用场景
\1. 发布推文。用户可以向其粉丝发布新消息(平均 4.6k请求/秒,峰值超过 12k请求/秒)。
\2. 主页时间线。用户可以查阅他们关注的人发布的推文(300k请求/秒)。
伸缩性挑战并不是主要来自微博量,而是来自扇出(fan-out)——每个用户关注了很多人,也被很多人关注。
两种解决方案(具体不展开,这里图文代码描述非常丰富)
\1. 发布微博时,将新微博插入全局微博集合。当用户请求自己的主页时间线时,首先找他关注的所有人,查询这些别关注用户发布的微博并按时间顺序合并。
\2. 为每个用户的主业时间线维护一个缓存,就像每个用户的推文收件箱。当用户发布微博,查找所有关注该用户的人,将新的微博插入到每个主页时间线缓存中。
如何描述性能
两个角度:
- 增加负载参数并保持系统资源(CPU、内存、网络带宽)不变时,系统性能将受到什么影响?
- 增加负载参数并希望保持性能不变,需要增加多少系统资源?
像 Hadoop 这种批处理系统,很关心吞吐量(throughput),即美妙可以处理的记录数量,活在特定规模数据集上运行作业的总时间。(理想情况下,批处理时间 = 数据集大小 ÷ 吞吐量)
像在线系统,最关心服务的响应时间(response time),即客户端发送请求到接受响应之间的时间。
> 延迟(latency)不同于响应时间(response time)。后者不仅包括实际服务时间,还包括网络延迟和排队延迟。而延迟是某个请求等待处理的持续时长,期间处于休眠等待服务。
发送重复同样请求,每个响应时间有不同。将响应时间作为可测量的数值分布,而不是一个数值。
平均响应时间,通常用算术平均值计算,但不能告诉维护者有多少用户经历了延迟。而典型(typical)响应时间是更好的指标。即,使用百分位点(percentiles)会更好。将响应时间按最快到最慢排序,中位数(median)在中间。这个能够知道典型场景下用户需要等待多长时间——一般用户请求的响应时间少于响应时间的中位数,另一半服务时间比中位数长。
响应时间的高百分位点非常重要,它直接影响用户的服务体验。为了弄清异常多糟糕,可以看更高的百分位点,如95、99、99.9百分位点。
> 例如亚马逊在描述内部服务的响应时间要求时以99.9百分位点为准,即使它只影响一千个请求中的一个。这是因为请求响应最慢的客户往往也是数据最多的客户,也可以说是最有价值的客户 —— 因为他们掏钱了
但是,优化 99.99 百分位点代价也是非常昂贵,即便亚马逊也难以承担这种成本。
百分位点常用于服务级别目标(SLO,service level objectives)和服务级别协议(SLA,service level agreements),即定义服务预期性能和可用性的合同(翻译的什么玩意…)。
排队延迟通常占告白氛围点响应时间很大一部分,又称为头部阻塞效应。
实践中百分位点
即便强调了很多次高百分位点,在并行调用的时候,最终用户请求还是需要等待最慢的并行调用完成。如果想讲响应时间百分点添加到服务监视仪表盘,还需要持续有效计算。一个简单的实现是在时间窗口中保存所有请求的响应时间列表,并每分钟对列表进行排序。
> 一些算法能够以最小的CPU和内存成本(如前向衰减 ,t-digest 或HdrHistogram )来计算百分位数的近似值
应对负载的方法
开始正式讨论伸缩性:当负载参数增加时,如何保持良好的性能?
适应小级别负载的架构不太可能应付 10 于此的负载。
人们常在纵向/垂直伸缩(scaling up,更强的机器)和横向/水平伸缩(scaling out,负载分配多台小机器)两个观点中对立。垮多台机器分配负载叫做无共享架构。单机器运行简单,但高端机器很贵。所以非常密集的负载常需要横向伸缩。
优秀架构会将两种方法结合,更简单也更便宜。
有些系统具有弹性,可以检测到负载增加时自动增加计算资源,而其他系统是手动伸缩的。如果负载难预测,弹性系统很有用。实际上手动伸缩系统更简单,意外操作更少。
跨多态机器部署无状态服务很简单,但将状态系统从单节点变为分布式就会引入很多复杂度。因此,尝试来说,应该把数据库放在单个节点上(纵向伸缩),知道伸缩成本或可用性需求来了不得不改为分布式。
> 可预见,未来分布式系统将成为默认配置。不仅可伸缩性好,易用性和可维护性也好。
没有万金油可伸缩架构。实际的问题更像是:读取量、写入量、要存储的数据量、数据复杂度、响应时间要求、访问模式等等问题大杂烩。
良好适配应用的可伸缩架构,是围绕假设(assumption)建立的:哪些操作是常见的?哪些操作是汉奸的?这就是之前提到的负载参数。假设错,工程投入白费,或者更糟糕。尤其早期创业公司和非正式产品中,产品需要快速迭代比克伸缩的假象负载要重要得多。
可维护性
软件大部分开销不是在最初开发阶段,而在持续维护阶段:漏洞修复、保持系统正常运行、调查失效、适配新的平台、为新的场景进行修改、偿还技术债、添加新的功能。
许多程序员不喜欢遗留(legacy)系统。各有各的不爽。
但有一种方式来改变这个现状,一来就做好:在设计之初就尽可能考虑减少维护期间的痛苦,从而避免自己的软件系统编程遗留系统。因此有三个设计原则:
- 可操作性。便于运维团队平稳运行。
- 简单性。消除尽可能多的复杂度,新工程师也能轻松理解(这和 API 简单性不一样)。
- 可演化性/可伸缩性/可修改性/可塑性。工程师未来能够轻松对系统更改,需求变化能够为新用用做适配。
同样的,没有简单解决方案。
可操作性:人生苦短,疼爱运维
有人说“好的运维能绕开垃圾软件的限制,而好的软件遇到垃圾运维也不能用”。尽管运维某些面可以,并且能够做到自动化,但最初建立正确运作的自动化机制还是取决于人。
一个优秀运维团队的典型职责如下:
* 监控系统的运行状况,并在服务状态不佳时快速恢复服务
* 跟踪问题的原因,例如系统故障或性能下降
* 及时更新软件和平台,比如安全补丁
* 了解系统间的相互作用,以便在异常变更造成损失前进行规避。
* 预测未来的问题,并在问题出现之前加以解决(例如,容量规划)
* 建立部署,配置、管理方面的良好实践,编写相应工具
* 执行复杂的维护任务,例如将应用程序从一个平台迁移到另一个平台
* 当配置变更时,维持系统的安全性
* 定义工作流程,使运维操作可预测,并保持生产环境稳定。
* 铁打的营盘流水的兵,维持组织对系统的了解。
良好可操作性,让运维能够专注于更高价值的事。一个数据系统可以做这些事:
* 好的监控,提供对系统内部状态和运行时行为的可见性(visibility)
* 自动化提供良好支持,将系统与标准化工具相集成
* 避免依赖单台机器(在整个系统继续不间断运行的情况下允许机器停机维护)
* 提供良好的文档和易于理解的操作模型(“如果做X,会发生Y”)
* 提供良好的默认行为,但需要时也允许管理员自由覆盖默认值
* 有条件时进行自我修复,但需要时也允许管理员手动控制系统状态
* 行为可预测,最大限度减少意外
简单性
小项目可以简单让人喜欢,代码有表现力。但项目大了后就非常复杂、难理解、增加维护成本。这种情况别叫做烂泥潭。
复杂了,就有各种问题:状态空间激增、模块间紧密耦合、纠结的依赖关系、不一致的命名和术语、解决性能问题的Hack、需要绕开的特例等等。
复杂了,时间和预算都会超支。
简化系统不一定意味减少功能,也可以消除额外复杂度。
> 额外复杂度 定义为:由具体实现中涌现,而非(从用户视角看,系统所解决的)问题本身固有的复杂度。
消除额外复杂度最好的工具之一是抽象(abstraction)。好的抽象可以将大量实现细节隐藏,仅保留简单易懂的外观。好的抽象也可以用用各类不同应用。相比重复造轮子,抽象更有效率,更有助于开发高质量软件。
> 如高级编程语言是一种抽象,隐藏了机器码、CPU寄存器和系统调用。 SQL也是一种抽象,隐藏了复杂的磁盘/内存数据结构、来自其他客户端的并发请求、崩溃后的不一致性。
可演化性:拥抱变化
系统需求永远在变,但处于常态变化。
> 例如:新的事实、出现意想不到的应用场景、业务优先级发生变化、用户要求新功能、新平台取代旧平台、法律或监管要求发生变化、系统增长迫使架构变化等。
敏捷(agile)工作模式为适应新的变化提供了框架。还有些很有用的工具:如测试驱动开发(TDD, test-driven development) 和 重构(refactoring) 。
敏捷技术大部分讨论都集中在相当小的规模(一个应用几个代码文件中)。本书将探索更大操作系统层面上提高敏捷性的方法,可有几个不同应用或服务组成。
> 例如,为了将装配主页时间线将方法从方法1变为方法2,如何“重构”微博的架构 ?